
12 Python ML/DS Libraries Used By Top Data Scientists
In this post, we talk about the top and most useful python libraries used by top data scientists around the world for ML and DS

The joy of coding Python should be in seeing short, consise, readable classes that express a lot of action in a small amount of clear code - not in the reams of trivial code that bores the reader to death.
-Guido Van Rossum
Introduction
With trillions of data being generated everyday, our work related to it is also becoming challenging. But, as they say- every problem has a creative solution, we are required to work on the combination of hard work and smart work to spare ourselves from weeks of compilation time.
Python is an exceptionally important programming language that is being used by industries across the world as their primary programming language. It's ocean of libraries has over 137k packages to help you with almost everything ranging from data cleaning, data manipulation, data analysis, data visualization to modelling, etc. Hence it is of great importance to learn about important libraries to be aware of because, you never know what challenge you may encounter in your upcoming project.
Top 12 Python libraries for ML/DS
1. Numpy
NumPy is a library for the Python programming language, adding support for large, multi-dimensional arrays and matrices, along with a large collection of high-level mathematical functions to operate on these arrays. NumPy in Python allows the user to write fast programs as long as most operations work on arrays or matrices instead of scalars.
18,600 starts on github is a strong evidence how crucial this library is for working with data science and ML projects.
You can find more details on its github page here.

Visit most famous SO questions for Numpy to have clear understanding, here.
2. Pandas
Pandas is a software library written for the Python programming language for data manipulation and analysis. Pandas allows importing data from various file formats such as comma-separated values, JSON, SQL, and Microsoft Excel. Pandas allows various data manipulation operations such as merging, reshaping, selecting, as well as data cleaning, and data wrangling features.
With over 31,400 stars on github, it is truly a starting point for any data enthusiast. Check out the github link here.

We have attached most trending questions for pandas on SO as an exercise for you to find out more, here.
3. pip
pip is a package-management system written in Python used to install and manage software packages. It connects to an online repository of public packages, called the Python Package Index.
One major advantage of pip is the ease of its command-line interface, which makes installing Python software packages as easy as issuing a command:
pip install some-package-nameUsers can also easily remove the package:
pip uninstall some-package-name7,500 stars on github do not reflect the importance of this package like no other packages can't be installed because of their master - pip. Find more details on its github page here.
Check out the most asked questions based on SO here.
4. Matplotlib
Matplotlib is a plotting library for the Python programming language and its numerical mathematics extension NumPy, which provides supports for multi-dimentional arrays. It is the most important data wrangling package, it works well with data science module inside the python ecosystem.
Matplotlib with its ability to create great visualizations has gathered 14,400 stars on its github page, here.
We recommend you to go through the most searched and voted questions for matplotlib on SO, here.
5. Scikit-learn
Scikit-learn is a free software machine learning library for the Python programming language. It features various classification, regression and clustering algorithms including support vector machines, random forests, gradient boosting, k-means and DBSCAN. Scikit-learn integrates well with many other Python libraries, such as Matplotlib and plotly for plotting, NumPy for array vectorization, Pandas dataframes, SciPy, and many more.
It's popularity among data enthusiasts can be seen by stars it has gathered on github - 47,600. For github links, visit here.
Also we have attached top questions from SO for scikit-learn here.
6. SciPy
SciPy is a free and open-source Python library used for scientific computing and technical computing. It contains modules for optimization, linear algebra, integration, interpolation, special functions, FFT, signal and image processing, ODE solvers and other tasks common in science and engineering. The basic data structure used by SciPy is a multidimensional array provided by the NumPy module.
It has over 8,700 stars on github, visit here for more details.
For SO questions related to SciPy trending right now, visit here.
7. TensorFlow
TensorFlow is a free and open-source software library for machine learning and artificial intelligence. It can be used across a range of tasks but has a particular focus on training and inference of deep neural networks. Tensorflow is a symbolic math library based on dataflow and differentiable programming. It is used for both research and production at Google.
TensorFlow was developed by the Google Brain team for internal Google use. It was released under the Apache License 2.0 in 2015.
TensorFlow is immensly popular with over 1,60,000 on github, check here.
We have attached mostly asked/voted questions on SO for TensorFlow, here.
8. PyTorch
PyTorch is an open-source machine learning library based on the Torch library, used for applications such as computer vision and natural language processing, primarily developed by Facebook's AI Research lab (FAIR). It is free and open-source software released under the Modified BSD license. Although the Python interface is more polished and the primary focus of development, PyTorch also has a C++ interface.
With over 51,500 stars on github, it's really picking up fast with TensorFlow.

Find top-most asked questions for PyTorch on SO, here.
9. Plotly
Plotly is a collaborative, web-based graphing and analytics platform. It allows users to import, copy and paste, or stream data to be analyzed and visualized. For analysis and styling graphs, Plotly offers a Python sandbox (NumPy supported), datagrid, and GUI. Python scripts can be saved, shared, and collaboratively edited in Plotly. The Plotly Python graphing library is a scientific graphing library. Graphs can be styled with Python and a GUI, and shared with a URL for others to view, collaborate, or save a copy.
It has over 10,400 stars on github and is one of the most sought out package for visualizations. Check here.
Check most voted/asked questions on SO here.
10. Statsmodel
Statsmodels is a Python package that allows users to explore data, estimate statistical models, and perform statistical tests. An extensive list of descriptive statistics, statistical tests, plotting functions, and result statistics are available for different types of data and each estimator. It complements SciPy's stats module.
Statsmodels is part of the Python scientific stack that is oriented towards data analysis, data science and statistics. 6,700 stars on github are an evidence of popularity of deep learning vs basic statistics.
Check out trending questions related to statsmodel on SO here.
11. XGBoost
XGBoost is an open-source software library which provides a regularizing gradient boosting framework for C++, Java, Python, R, Julia, Perl, and Scala. It works on Linux, Windows, and macOS. From the project description, it aims to provide a "Scalable, Portable and Distributed Gradient Boosting (GBM, GBRT, GBDT) Library". It runs on a single machine, as well as the distributed processing frameworks Apache Hadoop, Apache Spark, Apache Flink, and Dask.
It has gained much popularity and attention recently as the algorithm of choice for many winning teams of machine learning competitions.
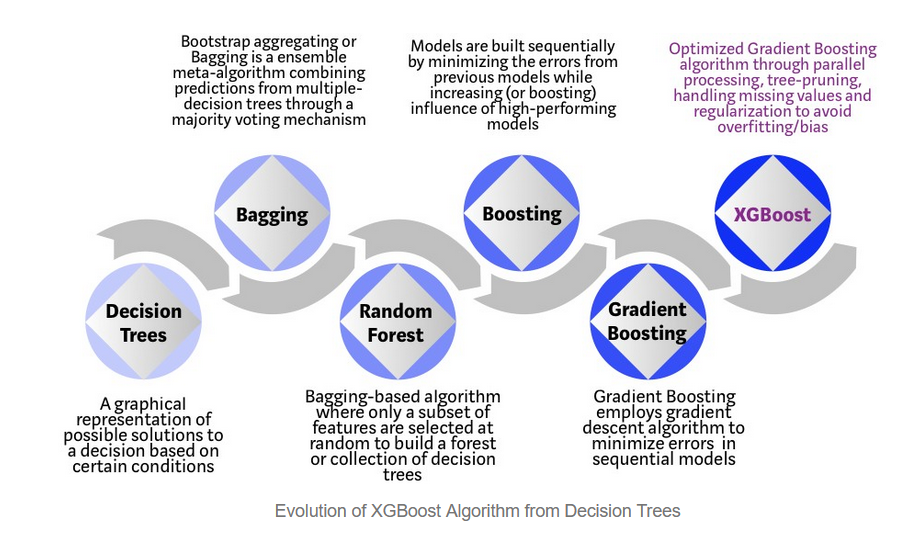
XGBoost comes as saviour when the data size exceeds certain terabytes threshold, and for all these reasons it has also gathered 21,700 stars on github, check here.
Check what people are finding interesting while working with XGBoost on SO channel here.
12. Scrapy
Scrapy is a free and open-source web-crawling framework written in Python. Originally designed for web scraping, it can also be used to extract data using APIs or as a general-purpose web crawler. It is currently maintained by Zyte formerly Scrapinghub, a web-scraping development and services company. Scrapy also provides a web-crawling shell, which can be used by developers to test their assumptions on a site’s behavior.

Don't forget to check out its github page having 41,900 stars, here.
Check out for top-most trending questions for scrapy from SO, here.
Conclusion
Each individual has their personal preferences for libraries based on their needs - hence this list above is a glimpse of the important ones according to us.
Choosing python library for yourself from thousands that are available, can be overwhelming. Hence, we highly recommend that one should always check documentation, Github link, SO platform, slack channel for any particular library he/she wishes to work with.
I hope this article encourages you to explore more amazing Python libraries available.
Bookmark us because we publish helpful articles everyday for you to level up in your data science journey.
Thank you visiting, stay tuned!


