
Exploring Agents: Get started by Creating Your Own Data Analysis Agent
LLMs have taken the world by storm, but on their own, they CAN'T do any particular task very well and produce unreliable results many a time. But if there's one thing that they do well, it is following cleverly, and meticulously crafted prompts. Let's use this ability of theirs to build some agents!

LLMs have taken the world by storm, but on their own, they CAN'T do any particular task very well and produce unreliable results many a time. But if there's one thing that they do well, it is following cleverly, and meticulously crafted prompts.
What are Agents?
In simple terms, an agent is a system that can perform certain tasks while having access to "tools". It uses these tools as needed and returns the response. Agents are useful for complex tasks as well, since they have the ability to handle errors from the previous action and iteratively try to correct them.
This approach allows combining the LLM with external knowledge sources as well as tools to breakdown and solve fairly complex tasks. You could think of agents as just LLMs making clever use of tools while thinking out step by step.
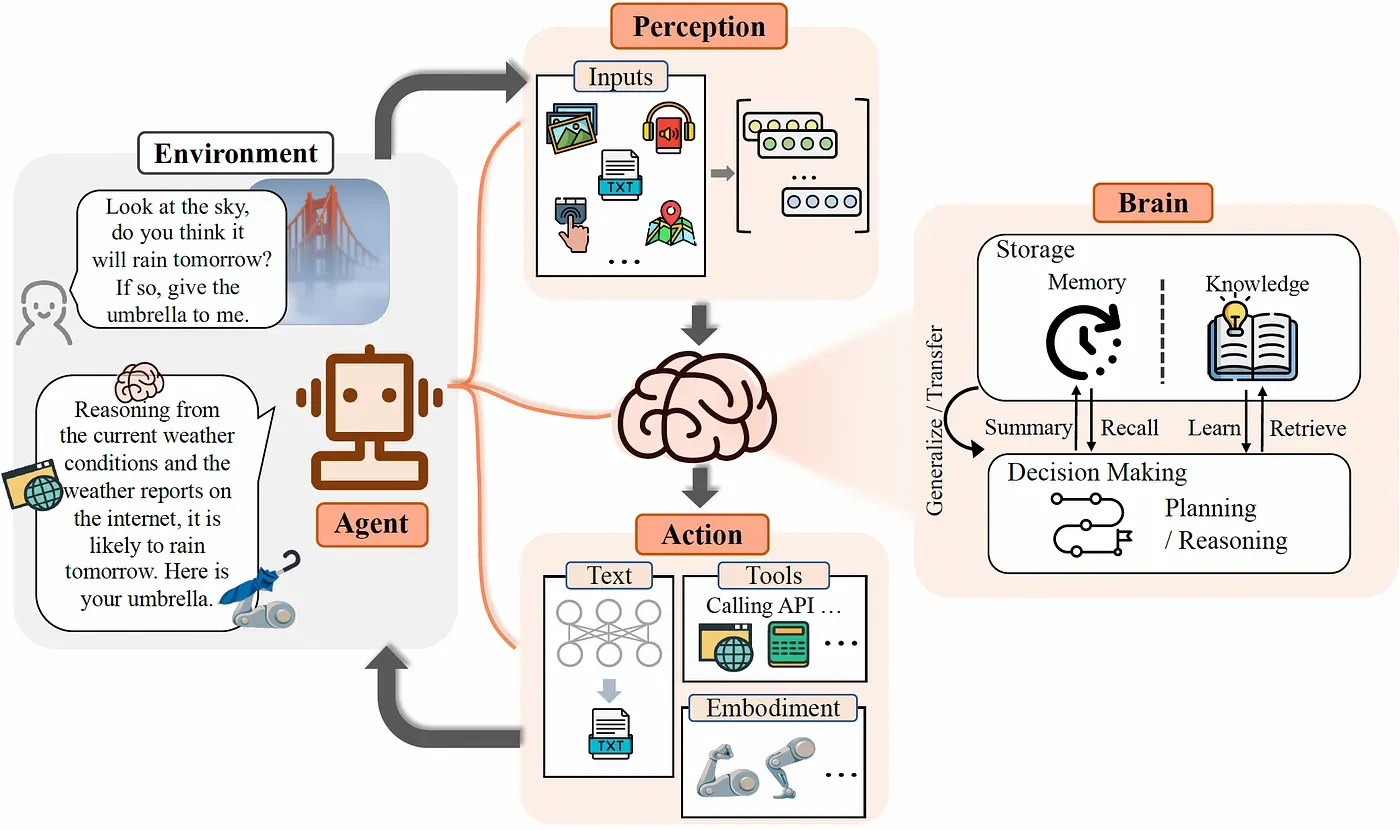
Let's get some hands-on experience with agents. We'll be building our own data analysis agent that can answer questions for us from SQL databases and CSV files using LangChain!
What is LangChain?
Language models are no longer just research lab playthings – they're the building blocks of the future. That's where LangChain comes in, a framework that empowers developers to harness the power of these models, turning complex prompts into real-world applications. Think "brain in a box" for your next software project.
But don't just take my word for it. Here are some cool projects built by the community using LangChain:
- Quiver - a second brain like Obsidian but supercharged with AI!
- DocsGPT - chat with any documents of your choice including project documentations!
- DataChad - chat with any data source!
Join LangChain's discord to be a part of the community, get help and do so much more.
Building a Data Analysis Agent
For someone who is getting started with data analysis or if you just want to focus on the problem at hand rather than expending your energy trying to write code to answer your questions, this agent can be very helpful.
For this example, we will be using the LangChain library to build an agent. Another popular alternative is LlamaIndex.
Here's the agent in action (on the play store apps dataset):
csv_agent.run("What is the average rating for the auto and vehicles category?")Output:
> Entering new AgentExecutor chain...
Thought: I need to filter the dataframe for the "Category" column where the value is "AUTO_AND_VEHICLES" and then calculate the average of the "Rating" column.
Action: python_repl_ast
Action Input: df[df['Category'] == 'AUTO_AND_VEHICLES']['Rating'].mean()
Observation: 4.19041095890411
Thought:The average rating for the "Auto and Vehicles" category is 4.19.
Final Answer: 4.19
> Finished chain.
'4.19'As you can see here, the agent is using a specific answering template that we'll be looking at in more detail later.
Let's build the agent component by component.
Necessary Imports and Setup
from langchain.chat_models import ChatOpenAI
from langchain.agents.agent_types import AgentType
from langchain_experimental.agents.agent_toolkits import create_csv_agent
from langchain.agents import create_sql_agent, load_tools
from langchain.sql_database import SQLDatabase
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.tools import HumanInputRun
from langchain.agents import AgentType, Tool, initialize_agent
from getpass import getpass
import osOPENAI_API_KEY = getpass()
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEYEnter your OpenAI API key when prompted.
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-1106")LangChain conveniently provides some useful agents pre-built for us while also giving the flexibility to build our own.
CSV Agent
(dataset)
csv_agent = create_csv_agent(
llm,
"googleplaystore.csv",
verbose=True,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)Let's try to run it:
csv_agent.run("Top 10 downloaded apps")Output
> Entering new AgentExecutor chain...
Thought: I need to sort the dataframe by the "Installs" column and then select the top 10 rows.
Action: python_repl_ast
Action Input: df.nlargest(10, 'Installs')
Observation: TypeError: Column 'Installs' has dtype object, cannot use method 'nlargest' with this dtype
Thought:The "Installs" column has dtype object, which means it's not in a numeric format. I need to convert it to a numeric format before sorting.
Action: python_repl_ast
Action Input: df['Installs'] = df['Installs'].str.replace('+', '').str.replace(',', '').astype(int)
Observation:
Thought:Now I can sort the dataframe by the "Installs" column and select the top 10 rows.
Action: python_repl_ast
Action Input: df.nlargest(10, 'Installs')
Observation: App Category Rating \
152 Google Play Books BOOKS_AND_REFERENCE 3.9
335 Messenger – Text and Video Chat for Free COMMUNICATION 4.0
336 WhatsApp Messenger COMMUNICATION 4.4
338 Google Chrome: Fast & Secure COMMUNICATION 4.3
340 Gmail COMMUNICATION 4.3
341 Hangouts COMMUNICATION 4.0
381 WhatsApp Messenger COMMUNICATION 4.4
382 Messenger – Text and Video Chat for Free COMMUNICATION 4.0
386 Hangouts COMMUNICATION 4.0
391 Skype - free IM & video calls COMMUNICATION 4.1
Reviews Size Installs Type Price Content Rating \
152 1433233 Varies with device 1000000000 Free 0 Teen
335 56642847 Varies with device 1000000000 Free 0 Everyone
336 69119316 Varies with device 1000000000 Free 0 Everyone
338 9642995 Varies with device 1000000000 Free 0 Everyone
340 4604324 Varies with device 1000000000 Free 0 Everyone
341 3419249 Varies with device 1000000000 Free 0 Everyone
381 69119316 Varies with device 1000000000 Free 0 Everyone
382 56646578 Varies with device 1000000000 Free 0 Everyone
386 3419433 Varies with device 1000000000 Free 0 Everyone
391 10484169 Varies with device 1000000000 Free 0 Everyone
Genres Last Updated Current Ver Android Ver
152 Books & Reference August 3, 2018 Varies with device Varies with device
335 Communication August 1, 2018 Varies with device Varies with device
336 Communication August 3, 2018 Varies with device Varies with device
338 Communication August 1, 2018 Varies with device Varies with device
340 Communication August 2, 2018 Varies with device Varies with device
341 Communication July 21, 2018 Varies with device Varies with device
381 Communication August 3, 2018 Varies with device Varies with device
382 Communication August 1, 2018 Varies with device Varies with device
386 Communication July 21, 2018 Varies with device Varies with device
391 Communication August 3, 2018 Varies with device Varies with device
Thought:I now know the final answer
Final Answer: The top 10 downloaded apps are Google Play Books, Messenger – Text and Video Chat for Free, WhatsApp Messenger, Google Chrome: Fast & Secure, Gmail, Hangouts, WhatsApp Messenger, Messenger – Text and Video Chat for Free, Hangouts, and Skype - free IM & video calls.
Works like a charm! Now, let's understand what it's doing.
print(csv_agent.agent.llm_chain.prompt.template)Output
You are working with a pandas dataframe in Python. The name of the dataframe is `df`.
You should use the tools below to answer the question posed of you:
python_repl_ast: A Python shell. Use this to execute python commands. Input should be a valid python command. When using this tool, sometimes output is abbreviated - make sure it does not look abbreviated before using it in your answer.
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [python_repl_ast]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
This is the result of `print(df.head())`:
{df_head}
Begin!
Question: {input}
{agent_scratchpad}
This is the clever prompt engineering I talked about earlier!
As we discussed earlier, agents make use of "tools" when needed. Here, the CSV Agent is given access to a tool called PythonREPL (an environment to run python code). The LLM is forced to think (or rather come up with responses) in a specific manner. This is modelled on the ReAct prompting paradigm that better enables LLMs to solve reasoning and decision making tasks.
The output of df.head() is also passed as an input to the model.
SQL Agent
First, install the Chinook database by following the instructions here. Give it some time after running the .read command.
db = SQLDatabase.from_uri("sqlite:////home/suchitg/agent_blog/Chinook.db")
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
sql_agent = create_sql_agent(
llm=llm,
toolkit=toolkit,
verbose=True,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)agent_executor.run("List the total sales per country. Which country's customers spent the most?")Output
> Entering new AgentExecutor chain...
Action: sql_db_list_tables
Action Input:
Observation: Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
Thought:The relevant tables for this question are Customer and Invoice. I should query the schema of these tables to see which columns I can use to calculate total sales per country.
Action: sql_db_schema
Action Input: Customer, Invoice
Observation:
CREATE TABLE "Customer" (
"CustomerId" INTEGER NOT NULL,
"FirstName" NVARCHAR(40) NOT NULL,
"LastName" NVARCHAR(20) NOT NULL,
"Company" NVARCHAR(80),
"Address" NVARCHAR(70),
"City" NVARCHAR(40),
"State" NVARCHAR(40),
"Country" NVARCHAR(40),
"PostalCode" NVARCHAR(10),
"Phone" NVARCHAR(24),
"Fax" NVARCHAR(24),
"Email" NVARCHAR(60) NOT NULL,
"SupportRepId" INTEGER,
PRIMARY KEY ("CustomerId"),
FOREIGN KEY("SupportRepId") REFERENCES "Employee" ("EmployeeId")
)
/*
3 rows from Customer table:
CustomerId FirstName LastName Company Address City State Country PostalCode Phone Fax Email SupportRepId
1 Luís Gonçalves Embraer - Empresa Brasileira de Aeronáutica S.A. Av. Brigadeiro Faria Lima, 2170 São José dos Campos SP Brazil 12227-000 +55 (12) 3923-5555 +55 (12) 3923-5566 luisg@embraer.com.br 3
2 Leonie Köhler None Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 +49 0711 2842222 None leonekohler@surfeu.de 5
3 François Tremblay None 1498 rue Bélanger Montréal QC Canada H2G 1A7 +1 (514) 721-4711 None ftremblay@gmail.com 3
*/
CREATE TABLE "Invoice" (
"InvoiceId" INTEGER NOT NULL,
"CustomerId" INTEGER NOT NULL,
"InvoiceDate" DATETIME NOT NULL,
"BillingAddress" NVARCHAR(70),
"BillingCity" NVARCHAR(40),
"BillingState" NVARCHAR(40),
"BillingCountry" NVARCHAR(40),
"BillingPostalCode" NVARCHAR(10),
"Total" NUMERIC(10, 2) NOT NULL,
PRIMARY KEY ("InvoiceId"),
FOREIGN KEY("CustomerId") REFERENCES "Customer" ("CustomerId")
)
/*
3 rows from Invoice table:
InvoiceId CustomerId InvoiceDate BillingAddress BillingCity BillingState BillingCountry BillingPostalCode Total
1 2 2009-01-01 00:00:00 Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 1.98
2 4 2009-01-02 00:00:00 Ullevålsveien 14 Oslo None Norway 0171 3.96
3 8 2009-01-03 00:00:00 Grétrystraat 63 Brussels None Belgium 1000 5.94
*/
Thought:I can calculate the total sales per country by joining the Customer and Invoice tables on the CustomerId column and summing the Total column from the Invoice table. Then I can order the results by the total sales in descending order to find out which country's customers spent the most.
Action: sql_db_query
Action Input: SELECT c.Country, SUM(i.Total) AS TotalSales
FROM Customer c
JOIN Invoice i ON c.CustomerId = i.CustomerId
GROUP BY c.Country
ORDER BY TotalSales DESC
Observation: [('USA', 523.06), ('Canada', 303.96), ('France', 195.1), ('Brazil', 190.1), ('Germany', 156.48), ('United Kingdom', 112.86), ('Czech Republic', 90.24), ('Portugal', 77.24), ('India', 75.26), ('Chile', 46.62), ('Ireland', 45.62), ('Hungary', 45.62), ('Austria', 42.62), ('Finland', 41.62), ('Netherlands', 40.62), ('Norway', 39.62), ('Sweden', 38.62), ('Spain', 37.62), ('Poland', 37.62), ('Italy', 37.62), ('Denmark', 37.62), ('Belgium', 37.62), ('Australia', 37.62), ('Argentina', 37.62)]
Thought:I now know the final answer
Final Answer: USA's customers spent the most.
> Finished chain.
"USA's customers spent the most."Let's have a look at the prompt template used by the SQL agent as well.
print(agent_executor.agent.llm_chain.prompt.template) Output
You are an agent designed to interact with a SQL database.
Given an input question, create a syntactically correct sqlite query to run, then look at the results of the query and return the answer.
Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most 10 results.
You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for the relevant columns given the question.
You have access to tools for interacting with the database.
Only use the below tools. Only use the information returned by the below tools to construct your final answer.
You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again.
DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database.
If the question does not seem related to the database, just return "I don't know" as the answer.
sql_db_query: Input to this tool is a detailed and correct SQL query, output is a result from the database. If the query is not correct, an error message will be returned. If an error is returned, rewrite the query, check the query, and try again. If you encounter an issue with Unknown column 'xxxx' in 'field list', use sql_db_schema to query the correct table fields.
sql_db_schema: Input to this tool is a comma-separated list of tables, output is the schema and sample rows for those tables. Be sure that the tables actually exist by calling sql_db_list_tables first! Example Input: table1, table2, table3
sql_db_list_tables: Input is an empty string, output is a comma separated list of tables in the database.
sql_db_query_checker: Use this tool to double check if your query is correct before executing it. Always use this tool before executing a query with sql_db_query!
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [sql_db_query, sql_db_schema, sql_db_list_tables, sql_db_query_checker]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought: I should look at the tables in the database to see what I can query. Then I should query the schema of the most relevant tables.
{agent_scratchpad}
If you look at here again, this agent uses a few tools as well. A tool is just a function the LLM will have to call.
Each response by the LLM is parsed (behind the scences by LangChain) and interpreted. E.g., the response in Action: is inferred as a function to be called. The output is fed back to the LLM and it again decides the next step to take and the action to be done. This is the core concept of how typical agents work.
An Agent using Agents
To solidify our understanding of tools, let's use the agents we created earlier as tools and create another agent!
tools = [
Tool(
name="CSV data interaction and QA agent",
func=csv_agent.run,
description="useful when you need to work with csv files. Input should be a fully formed question."
),
Tool(
name="SQL database interaction and QA agent",
func=sql_agent.run,
description="useful when you need to work with sql databases. Input should be a fully formed question."
),
HumanInputRun(description="You can ask a human for guidance when you are not sure what to do next or want to know the type of data to query. The input should be a question for the human.")
]The functions used to run the agents were sql_agent.run() and csv_agent.run(). Since tools are just functions, we add them as tools for our new agent. Apart from that, we also add the "human tool" so that the LLM can ask the human about the file type to query in case it is not clear. You can create custom tools using the Tool() class in LangChain.
data_analyst_agent = initialize_agent(
tools, llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True,
# Add a prefix to the prompt to remind the model to use the tool
agent_kwargs={"prefix": """Answer the following questions as best you can. Always clarify the filetype to query using the human tool first. You have access to the following tools:"""}
)Let's have a look at the prompt template ...
Answer the following questions as best you can. Always clarify the filetype to query using the human tool first. You have access to the following tools:
CSV data interaction and QA agent: useful when you need to work with csv files. Input should be a fully formed question.
SQL database interaction and QA agent: useful when you need to work with sql databases. Input should be a fully formed question.
human: You can ask a human for guidance when you are not sure what to do next or want to know the type of data to query. The input should be a question for the human.
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [CSV data interaction and QA agent, SQL database interaction and QA agent, human]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}... and test it out!
data_analyst_agent.run("How many categorical and continous variables are there in the playstore dataset?")Output
> Entering new AgentExecutor chain...
I need to determine the type of data in the playstore dataset.
Action: human
Action Input: How can I determine the type of variables in the playstore dataset?
How can I determine the type of variables in the playstore dataset?
Observation: its a csv file
Thought:I need to use the CSV data interaction and QA agent to analyze the playstore dataset.
Action: CSV data interaction and QA agent
Action Input: What are the categorical and continuous variables in the playstore dataset?
> Entering new AgentExecutor chain...
Thought: I can identify the categorical variables by looking for columns with non-numeric data, and the continuous variables by looking for columns with numeric data.
Action: python_repl_ast
Action Input: df.dtypes
Observation: App object
Category object
Rating float64
Reviews int64
Size object
Installs object
Type object
Price object
Content Rating object
Genres object
Last Updated object
Current Ver object
Android Ver object
dtype: object
Thought:The categorical variables are 'App', 'Category', 'Size', 'Installs', 'Type', 'Price', 'Content Rating', 'Genres', 'Last Updated', 'Current Ver', and 'Android Ver'. The continuous variables are 'Rating' and 'Reviews'.
Final Answer: Categorical variables: 'App', 'Category', 'Size', 'Installs', 'Type', 'Price', 'Content Rating', 'Genres', 'Last Updated', 'Current Ver', and 'Android Ver'. Continuous variables: 'Rating' and 'Reviews'.
> Finished chain.
Observation: Categorical variables: 'App', 'Category', 'Size', 'Installs', 'Type', 'Price', 'Content Rating', 'Genres', 'Last Updated', 'Current Ver', and 'Android Ver'. Continuous variables: 'Rating' and 'Reviews'.
Thought:I now know the final answer
Final Answer: Categorical variables: 'App', 'Category', 'Size', 'Installs', 'Type', 'Price', 'Content Rating', 'Genres', 'Last Updated', 'Current Ver', and 'Android Ver'. Continuous variables: 'Rating' and 'Reviews'.
> Finished chain.
"Categorical variables: 'App', 'Category', 'Size', 'Installs', 'Type', 'Price', 'Content Rating', 'Genres', 'Last Updated', 'Current Ver', and 'Android Ver'. Continuous variables: 'Rating' and 'Reviews'."Here's another query I ran on the Titanic dataset. I liked how objective GPT-3.5 was here.
data_analyst_agent.run("How does survivability vary across people boarding from different places in the titanic dataset?")Output
> Entering new AgentExecutor chain...
I need to analyze the Titanic dataset to compare survivability across different boarding places.
Action: human
Action Input: How can I access and analyze the Titanic dataset to compare survivability across different boarding places?
How can I access and analyze the Titanic dataset to compare survivability across different boarding places?
Observation: its a csv file
Thought:I should use the CSV data interaction and QA agent to analyze the Titanic dataset.
Action: CSV data interaction and QA agent
Action Input: Load the Titanic dataset and calculate the survivability for each boarding place.
> Entering new AgentExecutor chain...
Thought: I need to group the data by the 'Embarked' column and then calculate the mean of the 'Survived' column for each group.
Action: python_repl_ast
Action Input: df.groupby('Embarked')['Survived'].mean()
Observation: Embarked
C 0.553571
Q 0.389610
S 0.336957
Name: Survived, dtype: float64
Thought:I now know the final answer
Final Answer: The survivability for each boarding place is:
- C: 55.36%
- Q: 38.96%
- S: 33.70%
> Finished chain.
Observation: The survivability for each boarding place is:
- C: 55.36%
- Q: 38.96%
- S: 33.70%
Thought:The survivability varies across people boarding from different places in the Titanic dataset.
Final Answer: The survivability for people boarding from different places in the Titanic dataset is as follows:
- C: 55.36%
- Q: 38.96%
- S: 33.70%
> Finished chain.
The survivability for people boarding from different places in the Titanic dataset is as follows:
- C: 55.36%
- Q: 38.96%
- S: 33.70%Code
Code used in this blog: https://github.com/SuchitG04/data-analyst-agent
Follow the instructions in the README.md file to run the notebooks locally.
Summary
In this blog, we explored the creation of language model-based agents (LLM-based agents) for data analysis using LangChain. We built a CSV agent and an SQL agent, showcasing their construction and operation.
The article emphasized the clever use of prompts and how tools like PythonREPL and SQLDatabaseToolkit are integrated to enhance the agents' capabilities. We also created a composite agent using the CSV and SQL agents as tools, demonstrating a hierarchical approach for versatile tasks.
The blog concludes with a practical example, illustrating how the composite agent can answer data analysis questions. Overall, it highlights the potential of LLM-based agents in handling diverse data analysis tasks effectively.
Thank you for reading this blog. In the next blog post we'll be using the PandasAI library to analyse a Spotify dataset! PandasAI is a python library that integrates Gen AI into pandas, making data analysis conversational. Stay tuned for that!
About me
I am Suchit, a student and an aspiring ML researcher. Visit my website to know more about me!


