
Building a Deep Research Workflow with Python Pipelines
Dive into a Python-based approach that leverages web scraping, functional programming, and AI summarization to create a basic deep research workflow.

In today’s fast-paced world of information overload, finding a structured and efficient way to research topics is crucial. Imagine being able to automatically fetch, parse, and summarize vast amounts of online content with just a few lines of code. In this post, we'll dive into a Python-based approach that leverages web scraping, functional programming, and AI summarization to create a basic deep research workflow.
The Idea Behind the Pipeline
The heart of this workflow is the pipeline pattern.
Instead of writing monolithic code, you can break down the research process into modular steps that are easy to understand, maintain, and extend.
In our example, we chain together different functions using custom classes like Pipe and MapPipe—allowing us to process data sequentially, much like an assembly line.
How It Works:
- Search for Relevant Links:
The process begins by querying a search API with a keyword (e.g.,"cost of GPUs"). The functionget_search_result_linksperforms a Google search via an API call and retrieves a list of URLs related to your research topic. - Fetch and Process Web Pages:
With a list of URLs in hand, the workflow fetches each page’s HTML source usingget_html_source. The HTML content is then processed bytext_from_html, which uses BeautifulSoup to extract clean, readable text. - Summarize Website Content:
Each extracted text is sent to thesummarize_websitefunction. This function leverages the OpenAI API to generate concise bullet-point summaries from the web page content. - Compile a Final Report:
Finally, thecreate_reportfunction aggregates these summaries into a final, comprehensive report. The report contains an overview, key takeaways, and a conclusion—all rendered in Markdown for clarity and ease of sharing.
Diving Into the Code
Let's explore some of the key components:
Custom Pipe Operator Implementation
Python allows operator overloading, meaning you can define how operators like | behave for your own classes. When you use the expression A | B, Python will call the left operand’s __or__ method with the right operand, or if the left object doesn’t implement it, it tries the right operand’s __ror__ (reverse or) method
- Create a Pipeline Class: Define a class (e.g.
Pipe) with an__ror__method. The__ror__method should take the left-hand input and perform an action (like calling a function or method) with it, then return the result. Using__ror__ensures that even if the left object is a plain value (which doesn’t implement|), our Pipe class will handle the operation. - Store a Function/Operation: In the
Pipeclass, store a callable (function) that represents the API call or transformation. The__ror__will use this function to process the input. - Chainable Output: Have
__ror__return a result that can be piped into the next step. You can return a plain value (which would use the next pipe’s__ror__), or wrap it in aPipe/Pipeline object if you want to carry additional context.
class Pipe:
def __init__(self, func):
"""Wrap a function for pipeline usage."""
self.func = func
def __ror__(self, other):
# When used as: data | Pipe(func), this method is called.
return self.func(other)
# Define some pipeline functions
def add_prefix(data: str) -> str:
return f"Prefix: {data}"
def to_upper(data: str) -> str:
return data.upper()
# Wrap functions in Pipe
prefix_pipe = Pipe(add_prefix)
upper_pipe = Pipe(to_upper)
# Use the custom pipe operator
result = "hello" | prefix_pipe | upper_pipe
print(result) # Output: "PREFIX: HELLO"
The Pipe is already looking very useful.
We could start with a keyword, send it to a function that searches Google, then retrieve the results and summarise it for us into a comprehensive report.
One additional Pipe we need for the operation to be more wieldy is the MapPipe class.
To create a map operator in Python that applies a list of functions sequentially to each item in a list, you can use operator overloading (|) and functional programming techniques.
If I receive a list of search results, I would like to apply a function to each entry in the results list. In our example, I may start with a single keyword and then receive 10 links from a Search API call.
Then for each website link I would like to retrieve its contents and summarise it with an LLM.
A MapPipe would "map" these tasks to each search result.
Implementation of MapPipe Class:
- Define a
MapPipeclass that holds a list of functions. - Implement
__ror__(reverse or operator|) to:- Iterate over each item in the input list.
- Apply each function in the function list sequentially to the item.
- Collect the transformed items into a new list.
- Return the modified list after processing all items.
class MapPipe:
def __init__(self, *funcs):
"""Initialize with a sequence of functions."""
self.funcs = funcs
def __ror__(self, items):
"""Apply each function in funcs sequentially to each item in items."""
return [
self._apply_funcs(item) for item in items
]
def _apply_funcs(self, item):
"""Apply all functions sequentially to a single item."""
for func in self.funcs:
item = func(item)
return item
# Example transformation functions
def double(x): return x * 2
def increment(x): return x + 1
def square(x): return x ** 2
# Create a pipeline that applies double -> increment -> square
pipeline = MapPipe(double, increment, square)
# Example usage
data = [1, 2, 3, 4]
transformed_data = data | pipeline
print(transformed_data) # Output: [9, 25, 49, 81]
Explanation:
- We define a
MapPipeclass that takes multiple functions (*funcs). - The
__ror__(|) operator allows piping a list of items into theMapPipeinstance. _apply_funcs(item)iterates over the list of functions, applying them sequentially to each item.- Finally, a transformed list is returned.
The following functions are the necessary utility functions you need to perform various steps in your workflow.
Setup your OpenAI API Key in the appropriate environment variable, import the necessary libraries, define the custom classes.
import os
os.environ["OPENAI_API_KEY"] = "your_openai_api_key_here"
import requests
from bs4 import BeautifulSoup
from openai import OpenAI
class Pipe:
def __init__(self, func):
self.func = func
def __ror__(self, other):
return self.func(other)
class MapPipe:
def __init__(self, *funcs):
"""Initialize with a sequence of functions."""
self.funcs = funcs
def __ror__(self, items):
"""Apply each function in funcs sequentially to each item in items."""
return [
self._apply_funcs(item) for item in items
]
def _apply_funcs(self, item):
"""Apply all functions sequentially to a single item."""
for func in self.funcs:
item = func(item)
return item
Define the various utility functions.
# Utility Functions
@Pipe
def get_search_result_links(keyword):
print("Performing search on: ", keyword)
url = "https://www.searchapi.io/api/v1/search"
params = {
"engine": "google",
"q": keyword,
"api_key": "your_searchapi_key_here"
}
response = requests.get(url, params=params)
if response.status_code == 200:
data = response.json()
if "organic_results" in data and data["organic_results"]:
results = data["organic_results"]
links = [result.get("link", "No link available") for result in results]
return links
else:
return {"error": "No search results found."}
else:
return {"error": f"API request failed with status code {response.status_code}"}
def get_html_source(url):
print("retrieveing html from url: ", url)
try:
response = requests.get(url)
response.raise_for_status() # Raise HTTPError for bad responses (4xx or 5xx)
return response.text
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
return ""
def text_from_html(html):
print("Parsing text from html")
soup = BeautifulSoup(html, 'html.parser')
text = soup.get_text(separator=' ', strip=True)
print(text)
return text
def summarize_website(text):
print("Summarizing website")
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "developer", "content": "You are a helpful assistant."},
{
"role": "user",
"content": f"Summarize the following website into 3 to 5 bullet points:\n\n{text}"
}
]
)
return completion.choices[0].message.content
@Pipe
def create_report(results):
print("Creating report")
text = '\n'.join(results)
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "developer", "content": "You are a helpful assistant."},
{
"role": "user",
"content": f"Summarize the following website summaries into a final report with a summary, key takeaways and a conclusion:\n\n{text}"
}
]
)
return completion.choices[0].message.content
Now you can define your pipeline
pipeline = MapPipe(get_html_source, text_from_html, summarize_website)
And run the entire "chain" with your search keyword.
final_report = "cost of GPUs" | get_search_result_links | pipeline | create_report
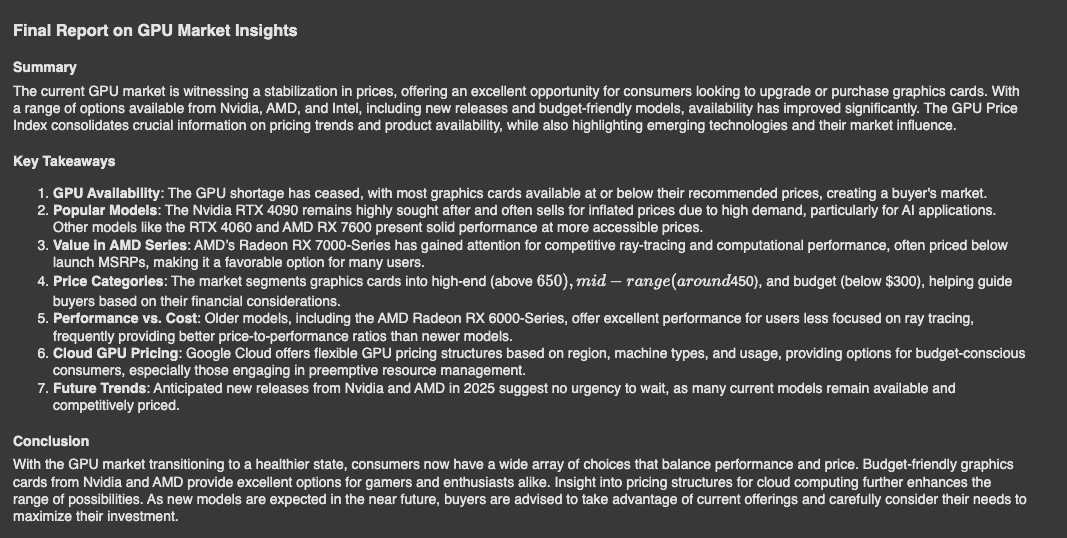
Finally, display the contents of final_report using Markdown.
from IPython.display import Markdown
Markdown(final_report)
We are not quite done!
Deep Research is not just about summarising results from various websites. The Deep Research workflows developed by OpenAI, Perplexity and Gemini require a large number of steps to be executed. These can be grouped into broad categories below.
- keyword/question understanding, re-writing and asking for clarifications.
- Identifying relevant sources via calling Search APIs with the relevant inputs to these APIs such as keywords and text phrases. You may even optimize for asking the Search API to look at certain kinds of information sources namely forums, social posts, authority websites, PDF files and so on.
- Parsing retrieved information.
- Summarising retrieved information and looking for next appropriate directions to pursue.
- Steps 1 to 4 can typically get out of hand without a stopping criteria. This is where reasoning models come in. When to appropriately conclude the process in terms of having answered the user's question comprehensively is a key component of a Deep Research workflow.
- Finally, developing an output in a certain format is critical to give the user the best experience of having received not only thorough research but packaged appropriately for consumption.
Deep Research is a AI-first product which has been capturing the imagination of knowledge workers who have been using it extensively on platforms like OpenAI and PerplexityAI.
If you are an AI Engineer looking to build Agentic workflows, start building your own workflows from scratch to truly understand how the various building blocks come together.


