
Data Scientists Reveal: 40 Best Cheat-Sheets on the Web
This article doesn't only link to the cheat-sheets but also some of the relevant sources which would help you in your python coding. This will help you get through some of the trickier tasks in data science

Introduction
Do you find yourself often confused about the different topics related to Data Science, Python, and similar disciplines? We’ve got you covered!
Take a peek below at our handy Data Science Cheat Sheets.
Here in this post, we have collated all the Cheat-sheets that can help you in your Data Science journey with Python. This collection of cheat sheets covers all the necessary data science techniques that will help you to get the most out of your Python code. It will help you perform data manipulations, machine learning, visualization, statistical analysis, and everything else you need to turn your data into something useful.
Why Python?
Python has rapidly become the most desired language in the job market. The wide applicability of Python, from web development to machine learning, is the reason why Python programmers are in high demand. Simple comparative analysis with the other machine learning languages shows its increasing popularity on Google Trends.
Following are the reasons we use python:
- Interpreted
- Platform Independent
- Embeddable
- Dynamically typed
This means that Python is interpreted directly into machine-understandable bytecode, unlike C, C++ or Java which require separate compilation and execution steps. It is due to these properties that Python runs on everything from digital watches to Mars Rover.
Note: In these cheat sheets we will be focusing only on Python 3 because on January 1st, 2020 the community decided to stop supporting Python 2 any further. This event was called Sunsetting Python 2.
Important CheatSheets For Data Science
1. Things you need to know before proceeding further - In the era of big data and artificial intelligence, data science and machine learning have become essential in many fields of science and technology. A necessary aspect of working with data is the ability to describe, summarize, and represent data visually. Python statistics libraries are comprehensive, popular, and widely used tools that will assist you in working with data.

2. Importing Data: Python Cheat Sheet - The next step after having the data is to load it to work on it and this step is called Data pre-processing which includes importing the data and cleaning it.


4. Here is a guide for creating strings in python - Like many other popular programming languages, strings in Python are arrays of bytes representing Unicode characters. However, Python does not have a character data type, a single character is simply a string with a length of 1. The link above is to help you play around with strings and learn more.

5. How you can store variables in the strings you created - Strings incorporate data. So you can “pack” them inside a variable. Doing so makes it easier to work with complex Python programs. The link would help you convert complex data into readable strings
6. Pandas Cheat Sheet for Data Science in Python - Pandas is a software library written for the Python programming language for data manipulation and analysis. In particular, it offers data structures and operations for manipulating numerical tables and time series.

7. NumPy Cheat Sheet: Data Analysis in Python - Numpy is one of the most commonly used packages for scientific computing in Python. It provides a multidimensional array object, as well as variations such as masks and matrices, which can be used for various math operations. Numpy is compatible with, and used by many other popular Python packages, including pandas and matplotlib.
8. Python Data Visualization: Bokeh Cheat Sheet - Python Bokeh is a Data Visualization library that provides interactive charts and plots. Bokeh renders its plots using HTML and JavaScript that uses modern web browsers for presenting elegant, concise construction of novel graphics with high-level interactivity. To know more about this visit the link above.

9. Matplotlib Cheat Sheet: Plotting in Python - Another data visualization library that is faster than bokeh as from the source code, it seems that bokeh is written purely in Python while Matplotlib is built on top of NumPy, which is significantly faster.
10. PySpark Cheat Sheet: Spark DataFrames in Python - Apache Spark is written in Scala programming language. To support Python with Spark, Apache Spark Community released a tool, PySpark. PySpark plays an essential role when it needs to work with a vast dataset or analyze them. This feature of PySpark makes it a very demanding tool among data engineers.

11. Scikit-Learn Cheat Sheet: Python Machine Learning - Scikit-learn (sklearn) is a free software machine learning library for the Python programming language. It features various classification, regression and clustering algorithms including support vector machines, random forests, gradient boosting, k-means, and DBSCAN, and is designed to interoperate with the Python numerical and scientific libraries NumPy and SciPy.
12. Python Seaborn: Statistical Data Visualization - Seaborn is a Python data visualization library based on matplotlib. It provides a high-level interface for drawing attractive and informative statistical graphics. Seaborn helps you explore and understand your data. Its plotting functions operate on data frames and arrays containing whole datasets and internally perform the necessary semantic mapping and statistical aggregation to produce informative plots. Its dataset-oriented, declarative API lets you focus on what the different elements of your plots mean, rather than on the details of how to draw them.
13. Data Science for Business Leaders - Data Science is no longer for techies only. It is imperative for business leaders to know the technical depth of the potential that their data holds. To keep pace with the technology, and to unlock the value of organizational data, it is important to understand the basics of data science so that you aren’t lost in jargon. To move ahead in data science here is a cheat sheet for your Business development using data.

14. SciPy Cheat Sheet: Linear Algebra in Python - SciPy is a free and open-source Python library used for scientific computing and technical computing. SciPy contains modules for optimization, linear algebra, integration, interpolation, special functions, FFT, signal and image processing, ODE solvers, and other tasks common in science and engineering.

15. From importing the data to cleaning Data manipulation or dropping of data before it is used in order to ensure or enhance performance, and is an important step in the data mining process. The phrase "garbage in, garbage out" is particularly applicable to data mining and machine learning projects where the data is cleaned and is ready to be analyzed using other tools.

16. A cheat sheet for plotting using Plotly - Plotly is a technical computing company headquartered in Montreal, Quebec, that develops online data analytics and visualization tools. Plotly provides online graphing, analytics, and statistics tools for individuals and collaboration, as well as scientific graphing libraries for Python, R, MATLAB, Perl, Julia, Arduino, and REST

17. Cheatsheet for creating applications using Flask - Flask is a web framework that provides libraries to build lightweight web applications in python.
Flask is a micro web framework written in Python. It is classified as a microframework because it does not require particular tools or libraries. It has no database abstraction layer, form validation, or any other components where pre-existing third-party libraries provide common functions.

18. Keras Cheatsheet for deep learning beginners - Keras is an API designed for human beings, not machines. Keras follows best practices for reducing cognitive load: it offers consistent & simple APIs, it minimizes the number of user actions required for common use cases, and it provides clear & actionable error messages. It also has extensive documentation and developer guides.
19. Spacy for NLP - Spacy is one of the best-known Python libraries for NLP. It relies on language-specific models and different sizes. Spacy NLP pipeline lets you integrate multiple text processing components of Spacy, whereas each component returns the Doc object of the text that becomes an input for the next component in the pipeline. We can easily play around with the Spacy pipeline by adding, removing, disabling, replacing components as per our needs. Moreover, you can also customize the pipeline components if required.
20. Tensorflow Cheatsheet - TensorFlow is an end-to-end open-source platform for machine learning and artificial intelligence. It can be used across a range of tasks but has a particular focus on the training and inference of deep neural networks. It has a comprehensive, flexible ecosystem of tools, libraries, and community resources that lets researchers push the state-of-the-art in ML, and developers easily build and deploy ML-powered applications.

21. Pytorch cheatsheets - PyTorch is an open-source machine learning library based on the Torch library, used for applications such as computer vision and natural language processing, primarily developed by Facebook's AI Research lab (FAIR). It is free and open-source software released under the Modified BSD license. Although the Python interface is more polished and the primary focus of development, PyTorch also has a C++ interface.
22. Selenium Cheatsheet - Selenium is an open-source umbrella project for a range of tools and libraries aimed at supporting web browser automation. Selenium provides a playback tool for authoring functional tests without the need to learn a test scripting language (Selenium IDE). It also provides a test domain-specific language (Selenese) to write tests in a number of popular programming languages, including JavaScript (Node.js), C#, Groovy, Java, Perl, PHP, Python, Ruby, and Scala.
23. Open CV Cheatsheet - OpenCV (Open Source Computer Vision Library) is a library of programming functions mainly aimed at real-time computer vision. In OpenCV, the CV is an abbreviation form of computer vision, which is defined as a field of study that helps computers to understand the content of digital images such as photographs and videos. The purpose of computer vision is to understand the content of the images. It extracts the description from the pictures, which may be an object, a text description, and three-dimension model, and so on.
For example, cars can be facilitated with computer vision, which will be able to identify and different objects around the road, such as traffic lights, pedestrians, traffic signs, and so on, and acts accordingly.

Some of the other CheatSheets are:
A Cheatsheet of Cheat Sheets
Start your coding -Cheatsheet
Probability Cheatsheet
Probability Distributions
One Source for all your probability formulas
Statistics Cheatsheet
Statistics Cheatsheet by MIT
Stats 100 final cheat sheet
Statistics summary sheet
frequently-used formulae and tables
Linear Algebra in just four pages
Calculus for machine learning
Deep Learning CheatSheets
1. Convolutional Neural Networks - In deep learning, a convolutional neural network (CNN, or ConvNet) is a class of artificial neural networks, most commonly applied to analyze visual imagery. They are also known as shift invariant or space invariant artificial neural networks (SIANN), based on the shared-weight architecture of the convolution kernels or filters that slide along input features and provide translation equivariant responses known as feature maps. Counter-intuitively, most convolutional neural networks are only equivariant, as opposed to invariant, to translation. They have applications in image and video recognition, recommender systems, image classification, image segmentation, medical image analysis, natural language processing, brain-computer interfaces, and financial time series.
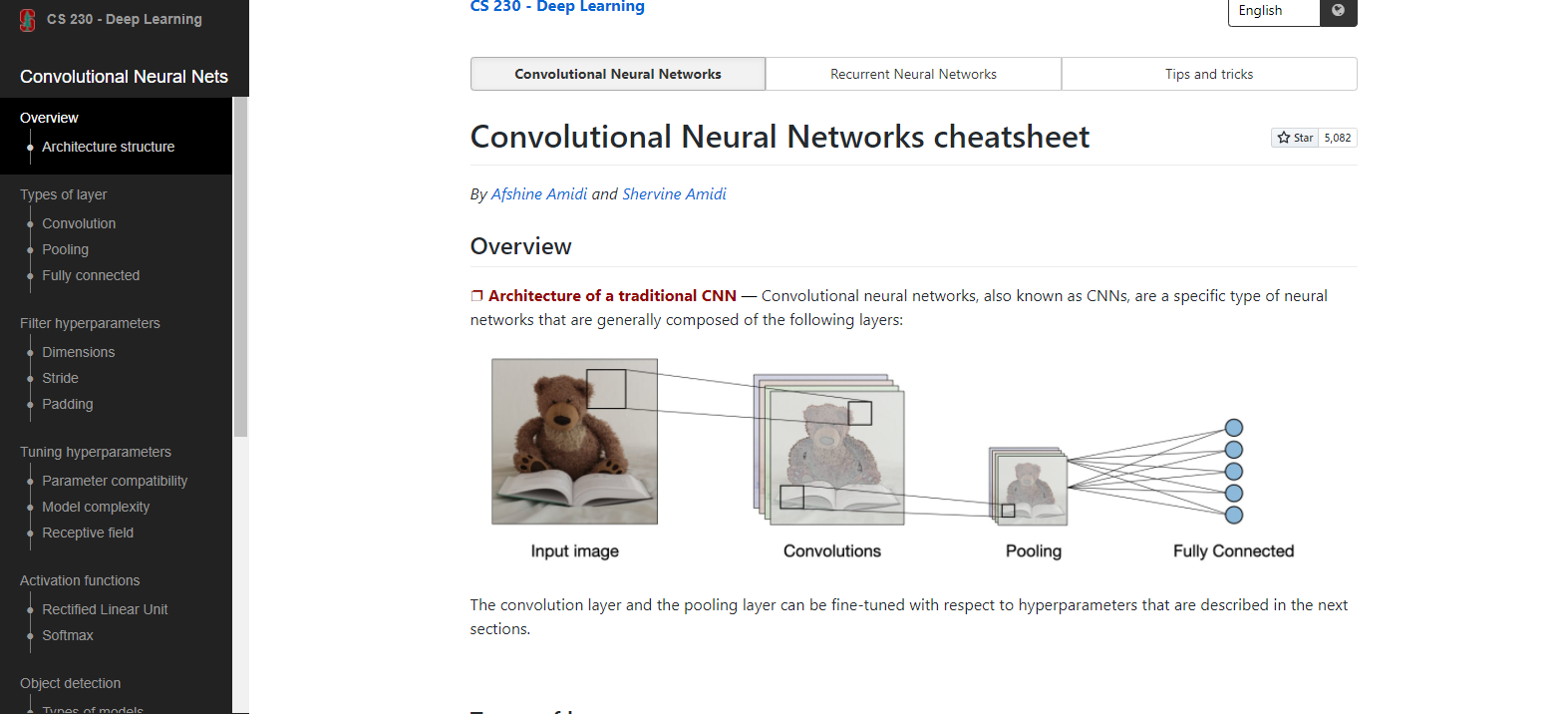
2. Recurrent Neural Networks - A recurrent neural network (RNN) is a class of artificial neural networks where connections between nodes form a directed graph along a temporal sequence. This allows it to exhibit temporal dynamic behavior. Derived from feedforward neural networks, RNNs can use their internal state (memory) to process variable-length sequences of inputs. This makes them applicable to tasks such as unsegmented, connected handwriting recognition, or speech recognition. Recurrent neural networks are theoretically Turing complete and can run arbitrary programs to process arbitrary sequences of inputs.

3. Few tips and tricks Cheatsheet for your Deep learning It has all the tips you need to start your deep neural networks containing both CNN and RNN for training for deep learning methods. It also delivers a host of other tips and tricks to enable you to obtain a strong understanding of the topic.
4. Artificial Intelligence and Neural networks Artificial neural networks (ANNs), usually simply called neural networks (NNs), are computing systems inspired by the biological neural networks that constitute animal brains. An ANN is based on a collection of connected units or nodes called artificial neurons, which loosely model the neurons in a biological brain. Each connection, like the synapses in a biological brain, can transmit a signal to other neurons. An artificial neuron receives a signal then processes it and can signal neurons connected to it. The "signal" at a connection is a real number, and the output of each neuron is computed by some non-linear function of the sum of its inputs. The connections are called edges. Neurons and edges typically have a weight that adjusts as learning proceeds. The weight increases or decreases the strength of the signal at a connection
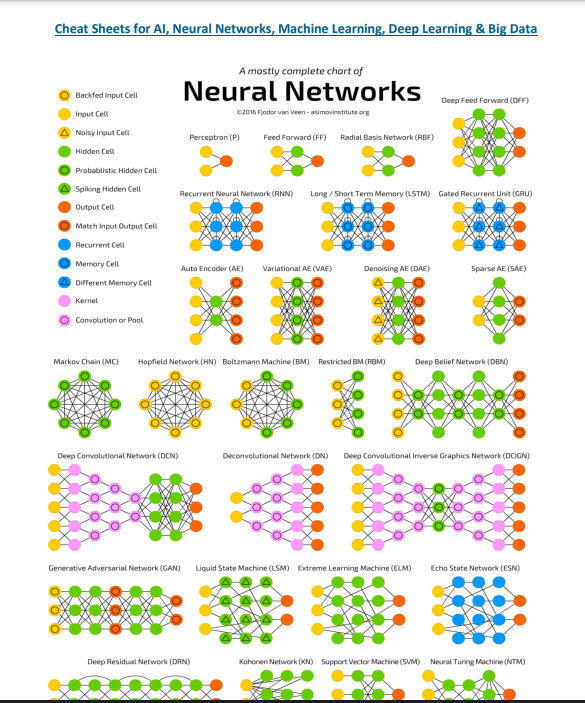
5. All your Data science compiled in 1 - This is the link to a 50 page summary of all the data science knowledge you need to have for forming the base of your python coding. If you're just getting started as a data scientist, this is a good first step.
Conclusion
This article doesn't only link to the cheatsheets but also some of the relevant sources which would help you in your python coding. This will help you get through some of the trickier tasks in data science. These are helpful for non-programmers as well!
We hope you found the information here useful.
Stay tuned for more!
Like us on Twitter
😎 😎
— datascience.fm (@DatascienceFm) January 20, 2022
Nobody finds Data Science cheat sheets better than us.
We bring you the most awesome Data Science cheat sheets on the WEB!!
👇👇👇https://t.co/tIBjP8ssdX
👆👆👆#python #datascience #cheatsheets pic.twitter.com/So4cydYoA0


