
Building a Local Arxiv Paper Search Engine
Discover how our local search engine for academic papers streamlines research, providing quick and relevant results through advanced data processing and semantic search!

Introduction

ArXiv.org is a treasure of knowledge, housing millions of research papers across various scientific disciplines. Every day, hundreds of new papers are uploaded, making it a bustling hub of cutting-edge ideas and discoveries. But let's face it, navigating this vast sea of information can be overwhelming, even for the most seasoned researchers.
We're about to embark on a journey that'll transform how you interact with scientific papers. Let's get our hands dirty and build something awesome!
Overview
In this blog post, we're going to dive into the world of semantic search and show you how to build your very own local ArXiv paper search engine. Trust me, it's cooler than it sounds! We'll explore how to harness the power of embeddings to create a search tool that actually understands the meaning behind your queries!
The following posts will have the mentioned content:
The second post will include enhancing search with Local LLMs where we would explore integrating local Large Language Models (LLMs) like Ollama or LlamaFile into our ArXiv search engine. We'll demonstrate how these models can improve search quality and provide more context-aware results, all while maintaining user privacy and reducing reliance on external APIs.
Our third installment will be on building a user-friendly interface with Streamlit, which will focus on transforming our search engine into a fully-fledged web application using Streamlit. We'll guide you through creating an intuitive interface and deploying the app to Google Cloud Run, making it accessible to users worldwide while leveraging cloud infrastructure for scalability.
Next, the fourth post would be based on empowering AI agents with ArXiv search. This will showcase how to turn our ArXiv search engine into a powerful tool for AI agents using the CrewAI library. We'll demonstrate how this integration can enable more sophisticated research automation, allowing agents to gather and analyze scientific literature autonomously.
Lastly, we will be automating research reports with CrewAI and ArXiv Search where we'll demonstrate how to combine our ArXiv search tool with web search APIs like Serper.ai to create a powerful research automation system using CrewAI. This post will guide you through developing a crew of specialized AI agents that collaborate to gather information, analyze scientific literature, and synthesize findings into a comprehensive PDF report on a specified topic.
Dataset for our project
We'll be leveraging the comprehensive ArXiv Dataset available on Kaggle (link provided below, can be directly downloaded into the system). This dataset offers metadata for over 1.7 million scholarly papers across various STEM fields. Here's what you need to know about our data source:
- Content: The dataset provides a JSON file containing metadata for each paper, including crucial information such as paper IDs, titles, authors, abstracts, and categories.
- Size: The metadata file is substantial, weighing in at about 4.31 GB, which gives us plenty of data to work with for our search engine.
- Structure: Each entry in the JSON file represents a paper and includes fields like:
- 'id': The ArXiv ID, useful for accessing the full paper
- 'title': The paper's title
- 'authors': Names of the paper's authors
- 'abstract': A summary of the paper's content
- 'categories': ArXiv categories/tags for the paper
- Updates: The dataset is updated monthly, ensuring we have access to recent publications.
- Accessibility: While we're using the metadata for our search engine, it's worth noting that the full PDFs are available through Google Cloud Storage for those interested in more in-depth analysis.
To download and explore more about the dataset, check out the link below!


Filtering out category of papers using jq
Firstly, what is jq? jq is a powerful command-line tool for processing JSON data. It allows users to filter, transform, and reshape JSON with simple, expressive commands. Written in C with no dependencies, jq is portable and easy to deploy. Its specialized syntax makes complex JSON manipulations straightforward, offering a concise alternative to general-purpose programming languages for JSON-related tasks. Whether extracting data, reformatting structures or performing aggregations, jq simplifies these operations, making it invaluable for developers and data analysts working with JSON in shell environments.
Refer to the link below for more information on jq!

Coming to our project, we will be focusing on a smaller section of the dataset to work with, particularly related to the computer science field.

To jot down the dataset for our use case, let's do the following:
Step 1: Installation of jq
For Windows:
winget install jqlang.jq
Linux: If you're on a Debian-based system (like Ubuntu)
sudo apt-get install jq
macOS:
brew install jq
Step 2: Navigate to the Dataset Directory
Based on where your dataset is downloaded, cd into the particular directory on command prompt/ other OS specific terminals.
Step 3: Executing the commands:
For this project, we will create a smaller dataset for faster execution, based on your interest of field and the computing power, these can be modified according to your choice.
We will pick up a dataset belonging to these 4 sub-categories under computer science:
- Artificial Intelligence
- Computation and Language
- Information Retrieval
- Human-Computer interaction
This is how the command would look like:
jq -c "select(.categories | contains(\"cs.AI\") and contains(\"cs.CL\") and contains(\"cs.IR\") and contains(\"cs.HC\"))" arxiv-metadata-oai-snapshot.json > cs_papers_final.jsonThis jq command filters the JSON file of arXiv papers (our entire dataset) which is arxiv-metadata-oai-snapshot.json , selecting only those categorized in all four specified computer science areas: AI, CL, IR and HC. It then saves these selected papers to a new file named cs_papers_final.json in a compact JSON format.
Step 4: Conversion of ndjson file to json
Processing the file in ndjson format and parsing it becomes really difficult, that is why we will convert our file into appropriate json format with clear square brackets and commas between objects. To do this, you can install ndjson-to-json library for quick conversion.
npm install ndjson-to-json
And convert the file accordingly:
ndjson-to-json cs_papers_final.json -o papers_dataset.json
Storing the data using sqlite-vec
Since we would be running our code on Kaggle notebook, we would want the dataset to be uploaded on Kaggle so that we can use it conveniently. For our project, the dataset looks as shown:

Once this is up, let's jump into the code to store the information on a database!
Firstly let's install sqlite-vec using pip install.
pip install sqlite-vecNext, to verify if sqlite and sqlite-vec is correctly installed, we write the following code to print the version of sqlite_vec installed:
import sqlite3
import sqlite_vec
db = sqlite3.connect(":memory:")
db.enable_load_extension(True)
sqlite_vec.load(db)
db.enable_load_extension(False)
vec_version, = db.execute("select vec_version()").fetchone()
print(f"vec_version={vec_version}")Output:
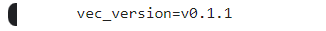
import sqlite3
import json
import sqlite_vec
# Connect to SQLite database
conn = sqlite3.connect('arxiv_papers.db')
conn.enable_load_extension(True)
# Register the extension with SQLite
sqlite_vec.load(conn)
cursor = conn.cursor()
# Create a table with columns to match the JSON structure
cursor.execute('''
CREATE TABLE IF NOT EXISTS papers (
id TEXT PRIMARY KEY,
authors TEXT,
title TEXT,
abstract TEXT,
update_date TEXT
)
''')
conn.commit()Next, we set up and configure the SQLite database for handling data:
- Database Connection: It establishes a connection to an SQLite database file named
arxiv_papers.db. If the file does not exist, SQLite will create it. - Enable Extension Support: The
enable_load_extension(True)method call allows SQLite to load external extensions, which is necessary for incorporating thesqlite_vecextension. - Create Table: Using the
cursor.executemethod, the script creates a table namedpapersif it doesn't already exist. This table has columns designed to hold various attributes of academic papers, such asid,authors,title,abstract, andupdate_date. Theidcolumn is specified as the primary key, ensuring each record is uniquely identifiable. We finally commit the connection.
Check if the db file is created in the kaggle/working directory:

We now connect to the database and insert the data:
import sqlite3
import json
# Connect to SQLite database
conn = sqlite3.connect('arxiv_papers.db')
cursor = conn.cursor()
# Load JSON data
with open('/kaggle/input/blog-number1/papers_dataset.json', 'r') as file:
data = json.load(file)
# Prepare the insert statements
papers_insert = '''
INSERT OR REPLACE INTO papers (id, authors, title, abstract, update_date)
VALUES (?, ?, ?, ?, ?)
'''
# Insert data
for paper in data:
# Insert into papers table
cursor.execute(papers_insert, (
paper['id'],
paper['authors'],
paper['title'],
paper['abstract'],
paper['update_date']
))
# Commit the changes and close the connection
conn.commit()
conn.close()
print("Data insertion complete.")
Insert Data: The script iterates through each paper in the loaded JSON data. For each paper, it executes the INSERT OR REPLACE statement using the data from the JSON, filling in the values for id, authors, title, abstract, and update_date.
Output:

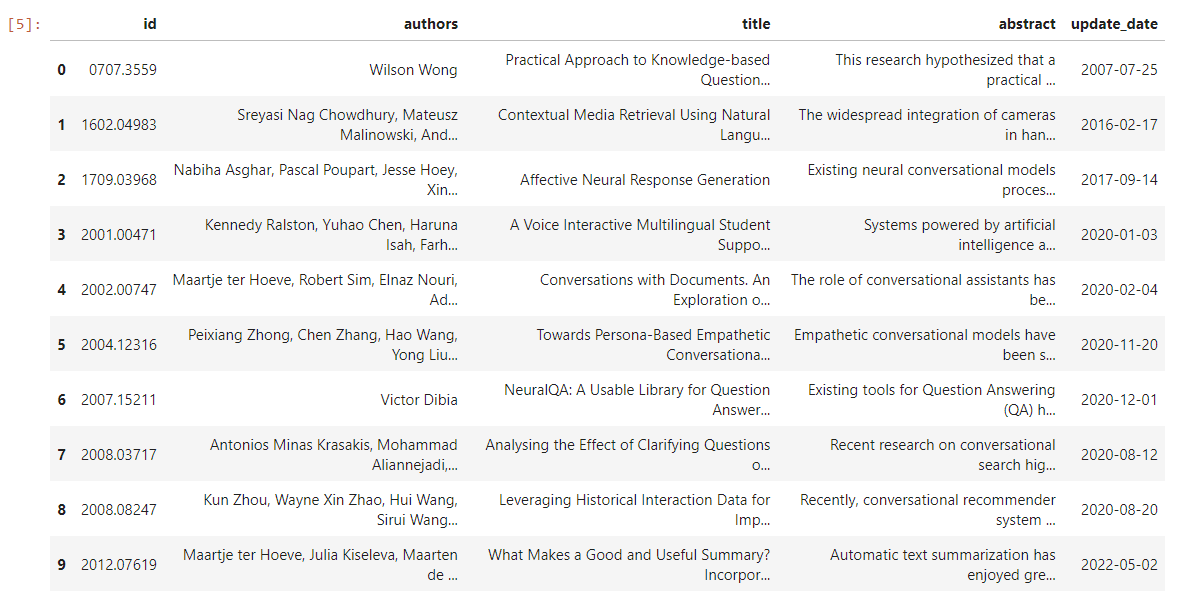
To verify if the data is inserted into the table, we print the first 10 rows:
import sqlite3
import pandas as pd
# Connect to the SQLite database
conn = sqlite3.connect('/kaggle/working/arxiv_papers.db')
# Query to select data from the papers table
query = "SELECT * FROM papers LIMIT 10;"
# Execute the query and load the result into a DataFrame
df = pd.read_sql_query(query, conn)
# Display the DataFrame
df
Output:
Binary Embeddings using Mixedbread AI
Binary embeddings using the Mixedbread AI model involve encoding text into compact binary vectors, which are derived from the model’s high-dimensional continuous embeddings. This process typically involves quantization techniques that convert floating-point embeddings into binary codes, preserving key semantic features while reducing their size. The binary representation is achieved through methods like hashing or product quantization, which map continuous vectors to binary codes. This approach leverages the model’s ability to capture semantic nuances despite the reduced precision, allowing for efficient storage and fast retrieval operations. The model maintains robust performance on tasks such as semantic textual similarity and retrieval by effectively balancing precision with computational efficiency.
Check out the code below to know how mxbai-embed-large-v1 can be used to produce binary embedding.
 mixedbread-ai
mixedbread-aiComing to our code, we shall install sentence_transformers to use the embedding model:
!pip install sentence_transformersimport sqlite3
import json
from sentence_transformers import SentenceTransformer
import numpy as np
import sqlite_vec
# Load the model
model = SentenceTransformer("mixedbread-ai/mxbai-embed-large-v1")
model = model.half() # Use fp16 for faster computation
# Connect to SQLite database
conn = sqlite3.connect('arxiv_papers.db')
conn.enable_load_extension(True)
sqlite_vec.load(conn)
cursor = conn.cursor()
# Recreate the virtual tables with the correct dimensions
cursor.execute('DROP TABLE IF EXISTS title_embeddings')
cursor.execute('DROP TABLE IF EXISTS abstract_embeddings')
cursor.execute('''
CREATE VIRTUAL TABLE title_embeddings USING vec0(title_embedding FLOAT[1024])
''')
cursor.execute('''
CREATE VIRTUAL TABLE abstract_embeddings USING vec0(abstract_embedding FLOAT[1024])
''')This code demonstrates the setup for managing and querying semantic embeddings in an SQLite database.
- We firstly load the SentenceTransformer model from the
mixedbread-ai/mxbai-embed-large-v1checkpoint. The model is then converted to use 16-bit floating-point precision (fp16) withmodel.half(), which speeds up computation by reducing memory usage, though it may slightly affect precision. - Next, we establish a connection to the SQLite database created before, named
arxiv_papers.db. It enables the loading of additional database extensions withconn.enable_load_extension(True), allowing for custom functionalities, such as thesqlite_vecextension, which is then loaded withsqlite_vec.load(conn). - Finally, we proceed to prepare the database schema by dropping any existing tables named
title_embeddingsandabstract_embeddings. It then creates two new virtual tables using thevec0extension. These tables are designed to store embeddings of titles and abstracts, respectively, each with a fixed vector dimension of 1024 floats. Thevec0extension facilitates efficient storage and querying of high-dimensional vectors within the database.
# Function to create embeddings
def create_embedding(text):
embedding = model.encode(text, convert_to_numpy=True, normalize_embeddings=True)
return embedding
# Function to insert embeddings
def insert_embedding(table_name, rowid, embedding):
embedding_json = json.dumps(embedding.tolist())
cursor.execute(f"INSERT OR REPLACE INTO {table_name} (rowid, {table_name[:-10]}embedding) VALUES (?, ?)",
(rowid, embedding_json))
# Fetch all papers
cursor.execute("SELECT rowid, title, abstract FROM papers")
papers = cursor.fetchall()
# Process each paper
for rowid, title, abstract in papers:
try:
# Create and insert title embedding
title_embedding = create_embedding(title)
insert_embedding('title_embeddings', rowid, title_embedding)
# Create and insert abstract embedding
abstract_embedding = create_embedding(abstract)
insert_embedding('abstract_embeddings', rowid, abstract_embedding)
# Commit after each paper to save progress
conn.commit()
print(f"Processed paper {rowid}")
except Exception as e:
print(f"Error processing paper {rowid}: {e}")
# Rollback the transaction in case of an error
conn.rollback()
# Close the connection
conn.close()
print("Embedding creation and insertion complete.")
create_embedding(text): Encodes input text into a normalized numpy array using theSentenceTransformermodel, which is configured for efficient computation withfp16.insert_embedding(table_name, rowid, embedding): Serializes the numpy embedding to JSON and inserts or updates it in the specified virtual table using an SQLINSERT OR REPLACEstatement.- Processing Loop: Executes an SQL query to retrieve
rowid,titleandabstractfrom thepaperstable. For each record, it computes embeddings for bothtitleandabstract, inserts these intotitle_embeddingsandabstract_embeddingstables respectively and commits the transaction. If an error occurs, it rolls back the transaction to maintain database integrity.
Output:
This process continues till all the papers are processed. Finally, we get the output:
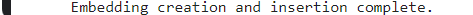
import sqlite3
import numpy as np
from sentence_transformers import SentenceTransformer
import sqlite_vec
import struct
# Load the model
model = SentenceTransformer("mixedbread-ai/mxbai-embed-large-v1")
model = model.half() # Use fp16 for faster computation
# Connect to SQLite database
conn = sqlite3.connect('arxiv_papers.db')
conn.enable_load_extension(True)
sqlite_vec.load(conn)
cursor = conn.cursor()The model mixedbread-ai/mxbai-embed-large-v1 is loaded and converted to half-precision (fp16) to speed up computation. The code then connects to a SQLite database (arxiv_papers.db), enables SQLite extensions, and loads the sqlite_vec extension to facilitate vector operations. Finally, it creates a cursor for executing SQL commands.
def serialize_f32(vector):
return struct.pack("%sf" % len(vector), *vector)
def search_papers(query, top_k=5):
# Create embedding for the query
query_embedding = model.encode(query, convert_to_numpy=True, normalize_embeddings=True)
query_embedding_bytes = serialize_f32(query_embedding)
# Fetch top-k similar papers using MATCH operator
cursor.execute('''
SELECT p.id, p.title, p.abstract, p.authors, p.update_date, te.rowid
FROM papers p
JOIN title_embeddings te ON p.rowid = te.rowid
WHERE te.title_embedding MATCH ? AND k = ?
ORDER BY distance
''', (query_embedding_bytes, top_k))
title_results = cursor.fetchall()
cursor.execute('''
SELECT p.id, p.title, p.abstract, p.authors, p.update_date, ae.rowid
FROM papers p
JOIN abstract_embeddings ae ON p.rowid = ae.rowid
WHERE ae.abstract_embedding MATCH ? AND k = ?
ORDER BY distance
''', (query_embedding_bytes, top_k))
abstract_results = cursor.fetchall()
# Combine and deduplicate the results
combined_results = title_results + abstract_results
seen_ids = set()
deduplicated_results = []
for result in combined_results:
if result[0] not in seen_ids:
seen_ids.add(result[0])
deduplicated_results.append(result)
return deduplicated_results[:top_k]We define two functions: serialize_f32 and search_papers. The serialize_f32 function converts the NumPy array (representing a vector) into a byte stream using the struct module, where each float32 value in the array is serialized.
The search_papers function performs a search for similar papers in a SQLite database based on a query. It first generates an embedding for the query and serializes this embedding. It then queries the database twice: once for title embeddings and once for abstract embeddings, using the MATCH operator to find similar embeddings. The MATCH operator is used in full-text search within SQLite, allowing for efficient similarity searches by comparing the serialized query embedding with stored embeddings. The results from both queries are combined, deduplicated by checking IDs, and then returned, limited to the top k results.
We finally print the results:
def print_results(results):
for i, result in enumerate(results, 1):
print(f"\nResult {i}:")
print(f"ID: {result[0]}")
print(f"Title: {result[1]}")
print(f"Authors: {result[3]}")
print(f"Update Date: {result[4]}")
print(f"Abstract: {result[2][:200]}...") # Print first 200 characters of abstract
def main():
while True:
query = input("\nEnter your search query (or 'quit' to exit): ")
if query.lower() == 'quit':
break
results = search_papers(query)
print_results(results)
conn.close()
if __name__ == "__main__":
main()Question 1:

Output:


Question 2:

Output:


How can you try it out?
I have uploaded all the files required on my Github repository given below!
ninaadpsSince I have dockerized the project, you can:
- Clone my repository using
git clone https://github.com/ninaadps/Local_Arxiv_paper_search- Build the docker image using
docker build -t my-arxiv-project .
- To run the container, you can run the below command on Windows Powershell
docker run -p 8888:8888 -v ${PWD}:/app my-arxiv-project
- Finally, open
http://localhost:8888on your browser. If it asks you for a token/password, check your terminal where the token would be provided, here is an example of how it looks, there is 'token=' mentioned:
Conclusion
Building a local search engine for academic papers can significantly enhance your research experience by making it easier to find relevant information quickly. By streamlining a dataset and leveraging various technologies, we’ve created a tool that efficiently handles and searches through academic papers.
Whether you’re a researcher, student or just someone passionate about learning, this search engine aims to help you access the knowledge you need more effectively. Thanks for following along, and we hope this tool proves valuable in your academic endeavors!



{kind=link}