
Exploring Cloudflare Vectorize: A Free Vector Database for Developers
Cloudflare has launched Vectorize, a highly accessible vector database that anyone can use, even on a Free Tier account! Vectorize enables developers to experiment with powerful vector search capabilities and build applications using advanced, unstructured data representations.

With the recent surge in popularity of AI-powered applications, vector databases have become essential tools for managing and querying dense embeddings—representing everything from images and text to user interactions.
Cloudflare has launched Vectorize, a highly accessible vector database that anyone can use, even on a Free Tier account! Vectorize enables developers to experiment with powerful vector search capabilities and build applications using advanced, unstructured data representations.
In this article, we’ll introduce Cloudflare Vectorize and walk through how to get started with FastText word vectors. FastText, a library developed by Facebook’s AI Research (FAIR) team, provides word embeddings that capture semantic meaning. We’ll show how to upload FastText word vectors into a Cloudflare Vectorize index to enable efficient similarity searches.
What Is Cloudflare Vectorize?
Cloudflare Vectorize is a vector database service that allows you to store and search embeddings (vectors) at scale. This type of database is ideal for applications involving similarity search, recommendation engines, and natural language processing (NLP) tasks, where complex, high-dimensional data needs to be quickly matched or analyzed.
The best part? Vectorize is accessible even on Cloudflare's Free Tier, making it ideal for individual developers, startups, or anyone wanting to explore vector search without incurring upfront costs. Vectorize indexes support millions of vectors, making it scalable and suitable for a variety of applications.
Setting Up Cloudflare Vectorize
To start using Vectorize, you’ll need a Cloudflare account. Sign up at Cloudflare if you don’t have an account yet, and navigate to the Vectorize documentation to set up your API token.
This token will authenticate requests for uploading and managing your vectors.
Experimenting with FastText Word Vectors on Cloudflare Vectorize
Now, let’s get practical. FastText embeddings are a great way to explore Vectorize because they are widely available, and they give us a way to test similarity search functionality.
Step 1: Install FastText (Optional)
If you’d like to experiment with FastText vectors, you can install FastText through pip if it isn’t already installed:
pip install fasttext
For this example, we’ll assume you already have a pre-trained FastText .vec file which you can get from https://fasttext.cc/docs/en/english-vectors.html
If you are executing the code in a Notebook (Google Colab is a great choice) you can issue the following commands to download the pre-trained word vectors.
!wget https://dl.fbaipublicfiles.com/fasttext/vectors-english/wiki-news-300d-1M.vec.zip
!unzip wiki-news-300d-1M.vec.zip
Step 2: Loading FastText Vectors
To read the FastText vectors, use the following code snippet. This code reads each word and its associated vector into a dictionary and batches them for uploading.
The reason we batch the vectors into a batch size of 1000 is to upload to Vectorize. In the next step we will discuss how to create the vector index and upload vectors to Vectorize in batches
import io
# Path to your FastText `.vec` file
fasttext_file = 'path_to_your_fasttext_file.vec' # Replace with your FastText file path
batch_size = 1000 # Batch size for upload
# Initialize an empty list to hold batches of vectors
batches = []
with io.open(fasttext_file, 'r', encoding='utf-8', newline='\n', errors='ignore') as fin:
n, d = map(int, fin.readline().split()) # First line contains total vectors and vector dimension
batch = []
for line in fin:
tokens = line.rstrip().split(' ')
word = tokens[0]
vector = list(map(float, tokens[1:])) # Convert vector to float list
# Prepare the vector object
vector_obj = {
"id": word, # Use the word as the unique ID
"values": vector # List of vector values
}
batch.append(vector_obj)
# Collect batches of specified size
if len(batch) == batch_size:
batches.append(batch)
batch = []
# Add any remaining vectors to the final batch
if batch:
batches.append(batch)
The great thing about Cloudflare's services is that all of their services can be accessed via REST API calls.
This makes it easy to use Python requests library and interact with their APIs. The documentation is comprehensive and with some trial and error and a lot of help from ChatGPT the code in step 3 shows you how you can upload the Fasttext vectors to Vectorize.
Step 3: Uploading Vectors to Cloudflare Vectorize
With the vectors loaded, we can now upload them to Cloudflare Vectorize. You’ll need your ACCOUNT_ID and AUTH_TOKEN, which you can find on your Cloudflare dashboard under your account settings.
The following code sends each batch to Vectorize in NDJSON format. NDJSON (Newline-Delimited JSON) is a format supported by Vectorize for bulk uploads.
import json
import requests
# Cloudflare API setup
ACCOUNT_ID = 'your_account_id' # Replace with your actual Cloudflare account ID
AUTH_TOKEN = 'your_auth_token' # Replace with your actual Cloudflare auth token
vectorize_index_url = f"https://api.cloudflare.com/client/v4/accounts/{ACCOUNT_ID}/vectorize/v2/indexes/fasttext-words/insert"
headers = {
"Authorization": f"Bearer {AUTH_TOKEN}",
"Content-Type": "application/x-ndjson"
}
# Loop through each batch of vectors and upload
for batch_num, batch in enumerate(batches, 1):
# Convert batch to NDJSON format
ndjson_data = "\n".join(json.dumps(vec) for vec in batch)
# Send POST request to upload batch
response = requests.post(vectorize_index_url, headers=headers, data=ndjson_data)
# Check response for success or failure
if response.json().get('success'):
print(f"Batch {batch_num} uploaded successfully: {len(batch)} vectors.")
else:
print("Failed to upload batch", batch_num)
print(response.status_code, response.json())
This script handles:
- Batch Processing: Breaks the vectors into batches of 1,000 for efficient uploading.
- NDJSON Format: Formats each batch into NDJSON for uploading.
- Cloudflare Vectorize API: Sends each batch to the API endpoint, verifying if each batch uploads successfully.
Remember to create the vector index in Vectorize first.
# Define the URL and headers
vectorize_endpoint = f"https://api.cloudflare.com/client/v4/accounts/{ACCOUNT_ID}/vectorize/v2/indexes"
headers = {
"Authorization": f"Bearer {AUTH_TOKEN}",
"Content-Type": "application/json"
}
# Define the payload with the index configuration
data = {
"config": {
"dimensions": 300,
"metric": "cosine"
},
"description": "Index of fasttext word vectors wiki-news-300d-1M",
"name": "fasttext-words"
}
# Send the POST request to create the index
response = requests.post(vectorize_endpoint, headers=headers, json=data)
# Check response and print the result
if response.json()['success']:
print("Index created successfully:")
print(response.json())
else:
print("Failed to create index")
print(response.json())
Stored the ~1M word vectors.
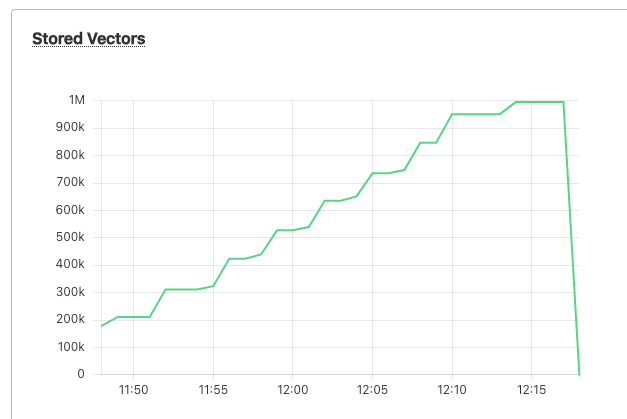
Failed to upload final batch
400 {'result': None, 'success': False, 'errors': [{'code': 40008, 'message': 'vectorize.upstream_error - id too long; max is 64 bytes, got 66 bytes'}], 'messages': []}
I got this error towards the final batch.
Turns out there was word that looked really malformed and exceeded 64 bytes.
This failed the entire batch.

Testing Vector Search with Cloudflare Vectorize
Once your vectors are uploaded, you can use Vectorize’s search API to find similar vectors. For example, you might submit a query vector and retrieve the top similar items. This is particularly useful in applications like search engines, recommendation systems, or any application where similarity-based matching is needed.
Let us search for words similar to a target word. This will require us to read the vec file, find a word (we will use a some random words) and then use its vector to query our index in Vectorize.
Here’s how you can implement this:
Step 1: Extract Vectors for Specific Keywords
We’ll read the FastText .vec file and store vectors only for the selected keywords.
import io
import requests
import json
# Define the path to your FastText `.vec` file
fasttext_file = 'path_to_your_fasttext_file.vec' # Replace with the path to your file
# Keywords to search for
keywords = {"king", "technology", "science", "artificial", "intelligence"}
# Dictionary to store word vectors for our keywords
keyword_vectors = {}
# Read the FastText file and extract vectors for the specified keywords
with io.open(fasttext_file, 'r', encoding='utf-8', newline='\n', errors='ignore') as fin:
n, d = map(int, fin.readline().split()) # Read total number of vectors and vector dimension
for line in fin:
tokens = line.rstrip().split(' ')
word = tokens[0]
# If the word is one of our keywords, store its vector
if word in keywords:
vector = list(map(float, tokens[1:])) # Convert vector to a list of floats
keyword_vectors[word] = vector
# Output the keyword vectors to confirm they are loaded correctly
print("Extracted vectors for the following keywords:")
for word, vector in keyword_vectors.items():
print(f"{word}: {vector[:10]}...") # Displaying first 10 dimensions for brevity
Step 2: Querying the Cloudflare Vectorize Index
Now, let’s use each of these vectors as an input query to Cloudflare Vectorize. For each keyword’s vector, we’ll send a query to retrieve similar vectors in the index.
Make sure to replace ACCOUNT_ID and AUTH_TOKEN with your actual Cloudflare account credentials.
# Cloudflare API setup for querying Vectorize
vectorize_query_url = f"https://api.cloudflare.com/client/v4/accounts/{ACCOUNT_ID}/vectorize/v2/indexes/fasttext-words/query"
headers = {
"Authorization": f"Bearer {AUTH_TOKEN}",
"Content-Type": "application/json"
}
# Function to query Vectorize with a vector
# Query the index with each keyword vector
for word, vector in keyword_vectors.items():
print(f"\nQuerying Vectorize index with the vector for '{word}':")
# Define the query payload with the vector
query_payload = {
"vector": vector, # Query vector
"top_k": 5 # Number of nearest neighbors to return
}
# Send POST request to the query endpoint
response = requests.post(vectorize_query_url, headers=headers, data=json.dumps(query_payload))
# Parse and display response
if response.json().get('success'):
results = response.json().get('result', [])
print("Query successful! Here are the top results:")
for result in results['matches']:
print(f"ID: {result['id']}, Score: {result['score']}")
else:
print("Query failed")
print(response.status_code, response.json())
Explanation of the Code:
- Extracting Keyword Vectors: We read the
.vecfile, and for each line (representing a word and its vector), check if it matches any keyword in our set. If it does, we store the vector in thekeyword_vectorsdictionary. - Querying Cloudflare Vectorize:
- For each keyword vector, we define a JSON payload (
query_payload) with the vector values and a parametertop_kto specify how many similar results we want. - We then send a POST request to the Cloudflare Vectorize query endpoint and print the results.
- For each keyword vector, we define a JSON payload (
- Results:
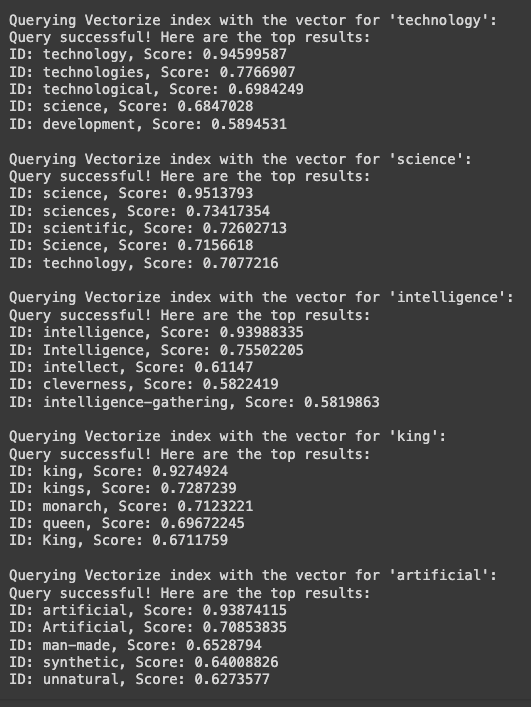
- The response returns IDs and similarity scores for the nearest vectors in the index. We display these results, giving an idea of which stored vectors are closest to the queried keyword vector.
Running the Code
Replace fasttext_file, ACCOUNT_ID, and AUTH_TOKEN with your specific values, and run the script. This process enables you to:
- Extract specific word embeddings (like
"king"and"technology") from FastText. - Query Cloudflare Vectorize to find similar embeddings in the index, which can be useful for applications such as synonym search, recommendation engines, or contextual queries.
Output of querying Vectorize is shown below.
Applications and Next Steps
Vectorize opens up a world of possibilities for developers.
By leveraging pre-trained embeddings from FastText or generating your own embeddings with models like BERT or Sentence-BERT, you can implement high-performance similarity search and vector-based applications. You might consider building:
- Semantic Search Engines: Use Vectorize to find similar documents or products based on embeddings.
- Recommendation Systems: Personalize recommendations by finding items with similar vectors.
- Conversational AI: Improve chatbot responses by retrieving similar queries or responses.
Conclusion
Cloudflare Vectorize makes it easy for anyone to experiment with vector search, whether for NLP tasks or other applications.
Combining FastText word embeddings with Vectorize is a great way to start experimenting with vector databases, especially since it’s available on Cloudflare's Free Tier.
The code above should help you get started uploading vectors to Vectorize and exploring similarity search capabilities in your applications.
Happy experimenting!


