
Empowering LLMs: Tools for Harnessing Human Expertise in AI Workflows
Unlock the potential of LLMs with cutting edge tools by leveraging human input and feedback in the workflow. Explore the seamless and powerful Argilla tool, enhancing LLMs for trustworthy and accurate language processing.

Large language models have had an enormous surge in popularity and represents a trend embraced by engineers across diverse fields. However, the optimization of these models hinges on a crucial collaboration with humans through the Human-in-the-Loop (HITL) approach.
But firstly, what is this all about?
Human-in-the-loop (HITL) approach
In simple words, it is a relationship between the humans and the models where human feedback refines and enhances the models for the continual improvement at the intersection of artificial intelligence and human expertise. It is basically a mechanism that allows continuous interaction between humans and machine learning models.
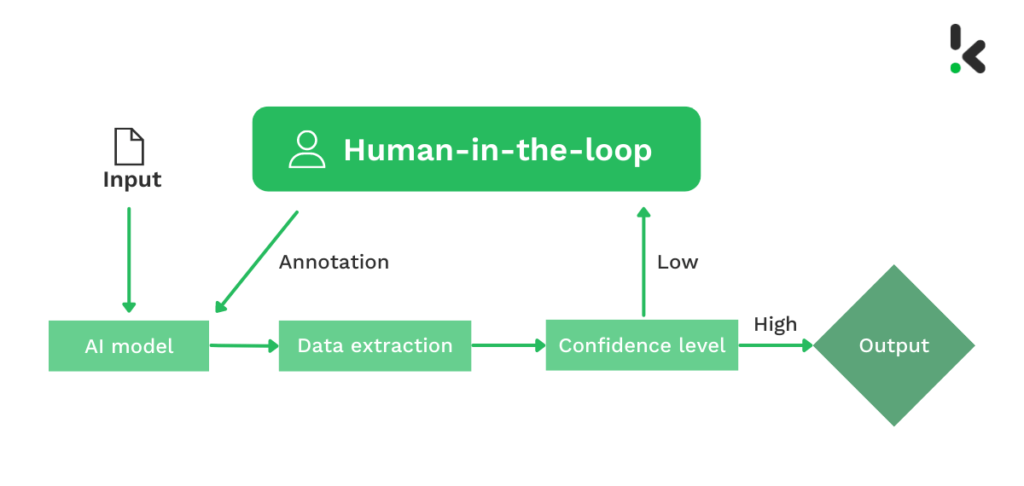
Why is it needed?
Most machine learning models never provide predictions with 100% confidence, thus HITL helps in dealing with uncertainty by giving direct feedback when predictions fall below a certain threshold, not only that, it forms a process of continuous learning so that it adapts to evolving patterns and new data, which can also cover up if there is insufficient training data. Therefore, the main purpose is to enhance precision and accuracy.
In correspondence to Large Language Models, it can help in :
- Increasing certainty in Language Understanding (Since LLMs operate on statistical patterns learned from vast amounts of text data).
- Handling Ambiguity and Nuance: LLMs may find it difficult in situations where the intended meaning is unclear or when there are multiple interpretations of a given text.
- Adaptation to Specific Domains: HITL can be employed to fine-tune or adapt LLMs to the nuances and specific terminology of a particular field.
- Quality Control and Bias Mitigation: HITL allows human annotators to review and correct outputs, because LLMs generate biased or inappropriate content based on the biases present in their training data.
- Improving Language Generation in Specialized Tasks: For very specific language tasks, such as technical writing, legal documentation, or medical reports, HITL increases the accuracy and relevance of LLM-generated content. Human experts can provide guidance and corrections in these specific domains.
Tools used for HITL
Argilla
Argilla is an open-source data curation platform for LLMs. Using this tool , one can build robust language models through faster data curation using both human and machine feedback. These provide support for each step in the MLOps cycle, from data labeling to model monitoring.
It is built on 5 core components:
- Python SDK
- FastAPI Server
- Relational Database
- Vector Database
- Vue.js UI
How to install Argilla?
For python, it is a simple statement:
pip install argillaTo get the develop version (which provides us with the most recent version but might be unstable)
pip install -U git+https://github.com/argilla-io/argilla.gitOn Docker, we can use Argilla Quickstart by running the following container on the terminal:
docker run -d --name quickstart -p 6900:6900 argilla/argilla-quickstart:latestAnother approach would be to use Hugging Face Spaces if we want to run Argilla workflows from Colab or remote notebooks:
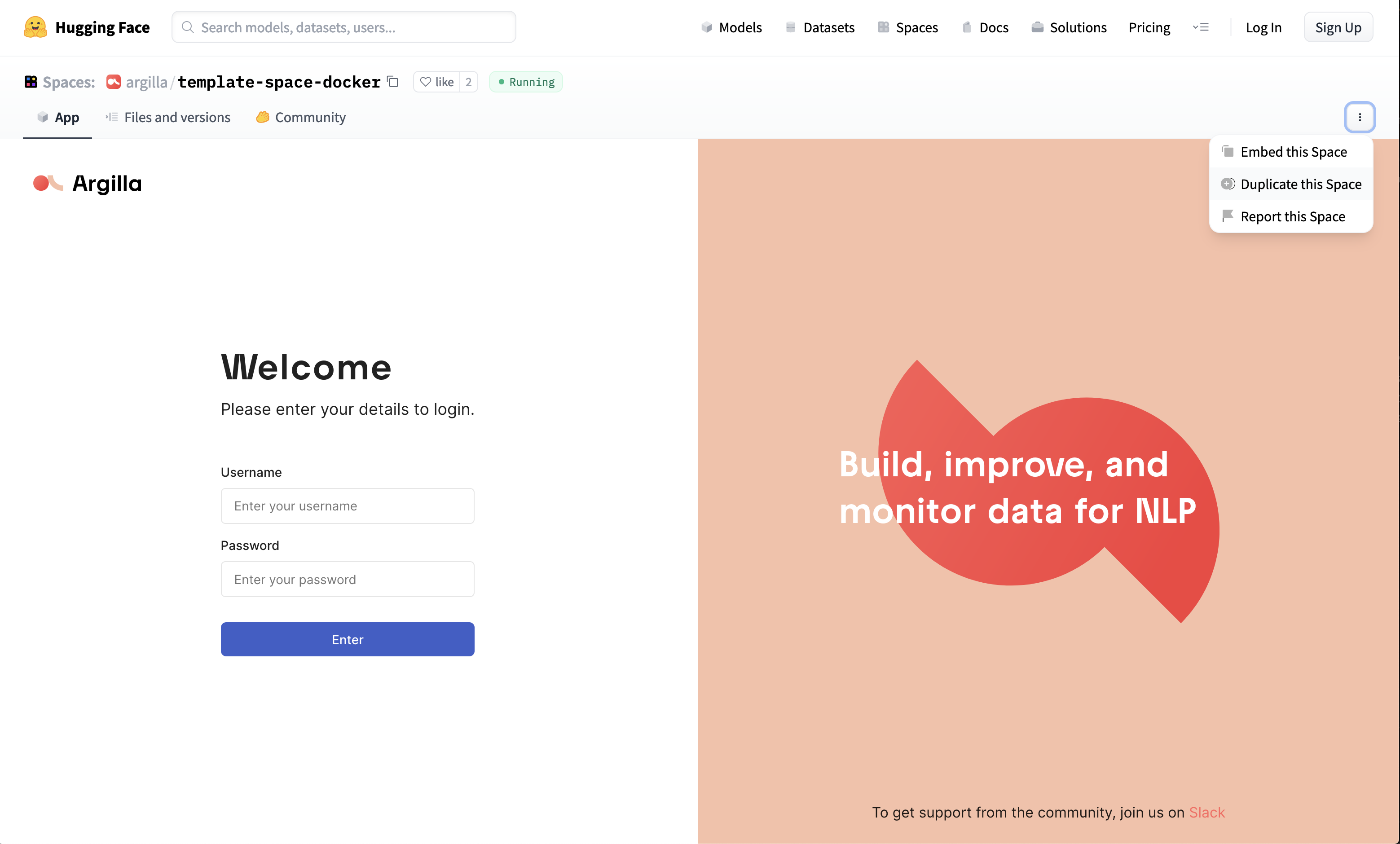
Login with username: admin
Password: 12345678
Here, it is recommended to use persistent storage layer provided by Hugging Face( otherwise, there will be loss of data after 48 hours of inactivity).
Argilla Feedback
Argilla Feedback is a powerful platform designed for collecting and managing feedback data from labelers or annotators. By understanding these entities and their relationships, we can effectively utilize the platform and leverage the collected feedback for various applications.

The dataset is the comprehensive collection of feedback records, each represented as a record. Records contain various fields, structuring information for labelers who use different question types such as TextQuestion, RatingQuestion, LabelQuestion, MultiLabelQuestion, and RankingQuestion. Guidelines are used to provide with crucial instructions, ensuring consistency, while responses capture individual labeler input, including identification and status.
Suggestions, leveraging automated aids enhance the feedback process and metadata holds additional record information.
Vectors represent semantic meanings for fields. This comprehensive system has the utmost purpose to streamline and optimize the feedback collection workflow.
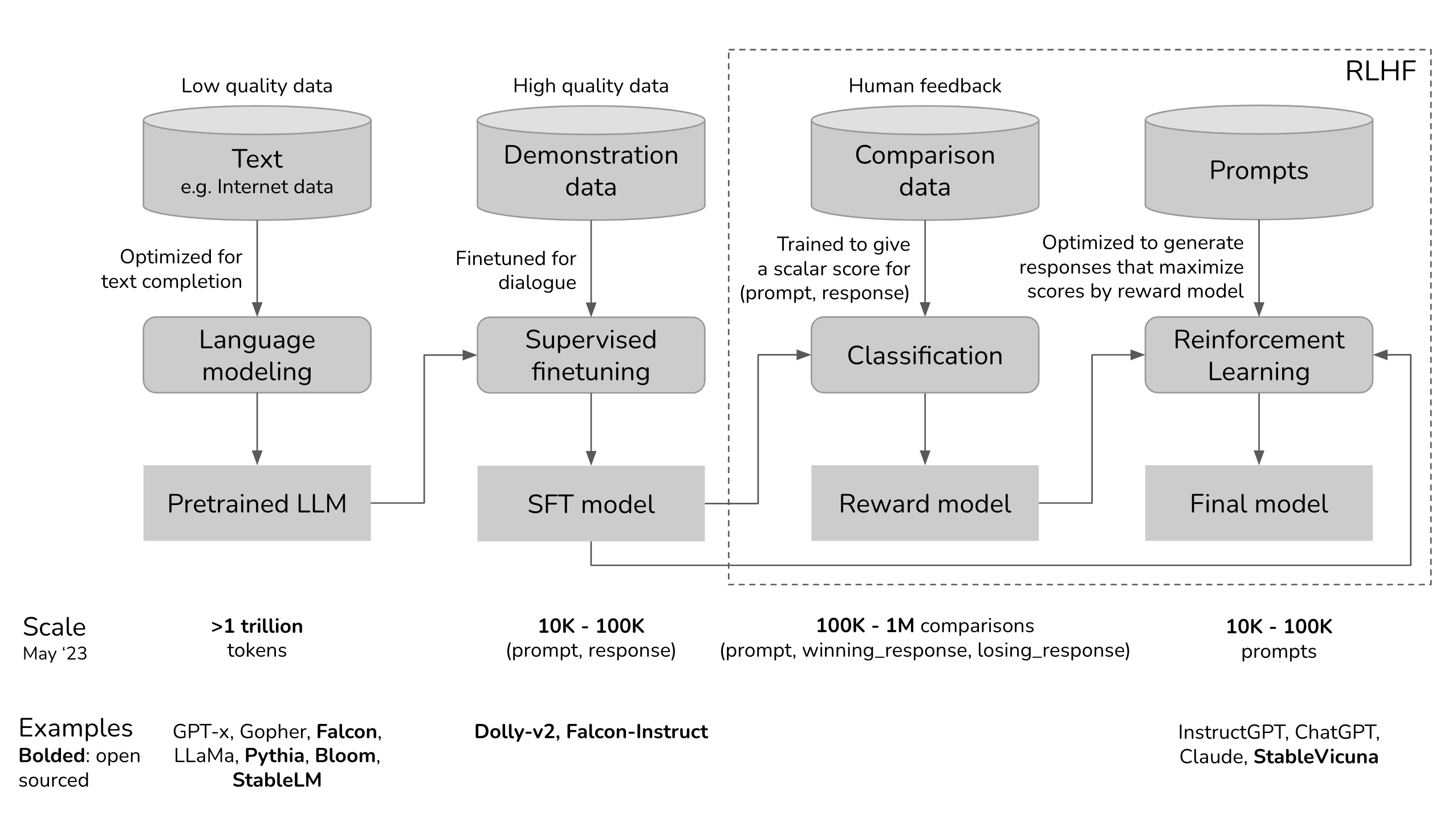
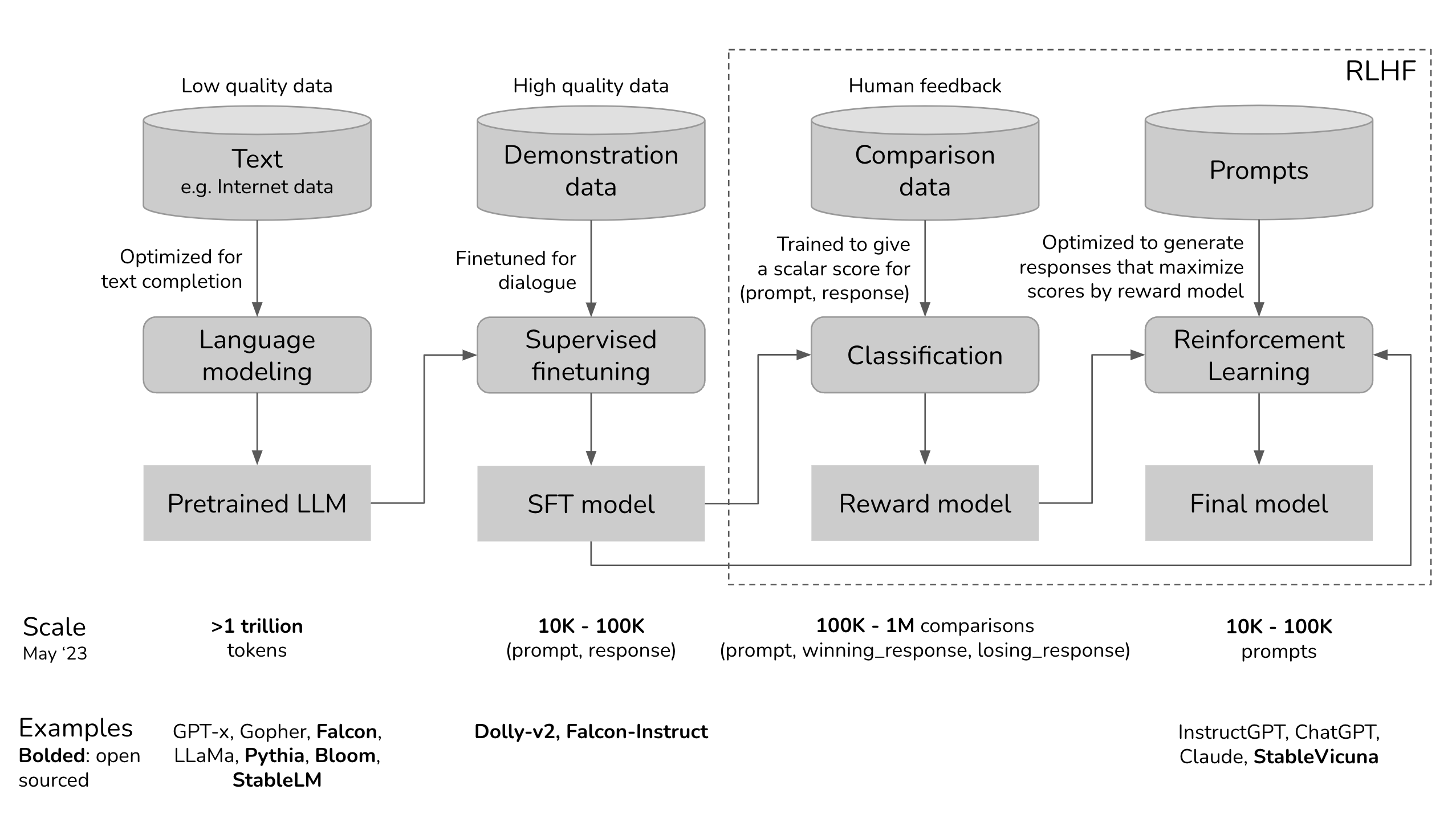
Serving as a critical solution for fine-tuning and Reinforcement Learning from Human Feedback (RLHF), this tool provides a flexible platform for the evaluation, monitoring, and fine-tuning tailored to enterprise use cases. Argilla Feedback boosts LLMs use cases through:
LLM Monitoring and Evaluation: Process for handling LLM projects by collecting both human and machine feedback. One way to do this is Argilla's integration with LangChain, which ensures continuous feedback collection for LLM applications.
Demonstration data collection: It helps in the gathering of human-guided examples, necessary for supervised fine-tuning and instruction-tuning.
Collection of Comparison Data: It plays an important significance in collecting comparison data to train reward models, which is a huge component of LLM evaluation and RLHF.
Reinforcement Learning: It assists in crafting and selecting prompts for the reinforcement learning stage of RLHF.
The figure below visualizes the key stages in training and fine-tuning LLMs. It highlights the data and expected outcomes at each stage, with particular emphasis on points where human feedback is incorporated.
Delving into Argilla Feedback with a Practical Use Case
Let us now discuss how we can use Argilla Feedback for fine-tuning and evaluating GPT-3.5 with human feedback for RAG.
Our main motive would be to build a hybrid RAG system (RAG using fine-tuned models), refer to this article for better understanding.
Step 1:
Firstly, install and launch Argilla and other required packages.
pip install argilla openai datasets llama-index unstructured -qqq# Import the needed libraries
import os
import json
import random
from tqdm import tqdm
import time
import matplotlib.pyplot as plt
import openai
import argilla as rg
from argilla.feedback import TrainingTask
from argilla.feedback import ArgillaTrainer
from typing import Dict, Any, Iterator
from typing import Union, Tuple, List
from llama_index import SimpleDirectoryReader, ServiceContext, download_loader
from llama_index.llms import OpenAI
from llama_index.evaluation import DatasetGenerator
from llama_index import VectorStoreIndex
from datasets import load_datasetThe other option of running Argilla is to use the Docker quickstart image or Hugging Face Spaces, where we need to init the Argilla client with the URL and API_KEY.
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
# Replace workspace with the name of your workspace
rg.init(
api_url="http://localhost:6900",
api_key="owner.apikey",
workspace="admin"
)For fine tuning and generation, we would need the OpenAI key.
os.environ['OPENAI_API_KEY'] = 'sk-...'
openai.api_key = os.environ["OPENAI_API_KEY"]Step 2:
Generating responses with LlamaIndex and GPT3.5
We shall use a dataset which contains generated responses from the generated questions regarding Argilla Cloud. This is the final dataset on Hugging Face.
# Read our source questions
dataset = load_dataset("argilla/cloud_assistant_questions")Next, let us index our document and inference the language model to retrieve relevant information from the unstructured document in response to a set of questions in the dataset.
# Read and parse the document using Unstructured
UnstructuredReader = download_loader("UnstructuredReader", refresh_cache=True)
loader = UnstructuredReader()
# You can download this doc from: https://huggingface.co/datasets/argilla/cloud_assistant_questions/raw/main/argilla_cloud.txt
documents = loader.load_data("argilla_cloud.txt")
# Set up the Llama index context
gpt_35_context = ServiceContext.from_defaults(
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.3)
)
# Index the document and set up the engine
index = VectorStoreIndex.from_documents(documents, service_context=gpt_35_context)
query_engine = index.as_query_engine(similarity_top_k=2)
contexts = []
answers = []
questions = dataset["train"]["question"]
# Inference over the questions
for question in tqdm(questions):
response = query_engine.query(question)
contexts.append([x.node.get_content() for x in response.source_nodes])
answers.append(str(response))Here is an example of a question, the answer and the context:
# Show an example of q, a, and context
print(f"Question: {questions[0]}")
print(f"Answer: {answers[0]}")
print(f"Context: {contexts[0]}")Output
Question: What is the ticketing system used by Argilla for customer support?
Answer: The ticketing system used by Argilla for customer support is not specified in the given context information.
Context: ["This process ensures the client administrator has full control over their team's access and can manage their workspace efficiently.Plans The plans for the Argilla Cloud service depend on the volume of records processed, with several tiers available to suit varying needs.Each tier has a corresponding monthly and annual price, with a 10% discount applied to the annual pricing option.The tier selection and associated price will be determined by the client's selection in the Service Order Form section of the Terms of Service document.Plans are: Starter 1 Million records Base 3 Million records Medium 4 Million records Large 6 million records\n\nSupport Argilla Cloud offers comprehensive support services to address various issues that may arise during the use of our service.Support levels are categorized into four distinct tiers, based on the severity of the issue, and a separate category for feature requests.The support process, response times, and procedures differ for each category.(1) Critical Issues Critical issues are characterized by: Severe impact on the Service, potentially rendering it completely non-functional.Disruption of critical service operations or functions.Obstruction of entire customer workflows.In the case of a critical issue, Argilla will: Assign specialist(s) to correct the issue on an expedited basis.Provide ongoing communication on the status via email and/or phone, according to the customer's preference.Begin work towards identifying a temporary workaround or fix.(2) Major Issues Major issues involve: Limited functionality of the Service.Service instability with periodic interruptions.Material service interruptions in mission-critical functions.Time-sensitive questions impacting performance or deliverables to end-clients.Upon encountering a major issue, Argilla will: Assign a specialist to begin a resolution.Implement additional, escalated procedures as reasonably determined necessary by Argilla Support Services staff.(3) Minor Issues Minor issues include: Errors causing partial, non-critical functionality loss.The need for clarification on procedures or information in documentation.Errors in service that may impact performance deliverables.(4) Trivial Issues Trivial issues are characterized by: Errors in system development with little to no impact on performance.Feature Requests Feature requests involve: Requesting a product enhancement.For feature requests, Argilla will: Respond regarding the relevance and interest in incorporating the requested feature.In summary, Argilla Cloud's support services are designed to provide timely and efficient assistance for issues of varying severity, ensuring a smooth and reliable user experience.All plans include Monday to Friday during office hours (8am to 17pm CEST) with additional support upon request.The Support Channels and features of each tier are shown below:\n\nStarter: Slack Community.Severity 1 - Response time < 4 hours.Severity 2 - Response time < 8 hours.Severity 3 - Response time < 48 hours.Severity 4 not specified.Base: Ticketing System, Severity 1 - Response time < 4 hours.Severity 2 - Response time < 8 hours.Severity 3 - Response time < 24 hours.Severity 4 not specified.Medium: Ticketing System and dedicated Slack channel, Severity 1 - Response time < 4 hours.Severity 2 - Response time < 8 hours.Severity 3 - Response time < 24 hours.Severity 4 one week\n\nLarge: Ticketing System and dedicated Slack channel, Severity 1 - Response time < 4 hours.Severity 2 - Response time < 8 hours.Severity 3 - Response time < 24 hours.Severity 4 one week.Data backup and recovery plan Argilla Cloud is committed to ensuring the safety and availability of your data.Our system is designed to run six data backups per day as a standard procedure.These backups capture a snapshot of the system state at the time of the backup, enabling restoration to that point if necessary.Our Recovery Point Objective (RPO) is four hours.This means that in the event of a system failure, the maximum data loss would be up to the last four hours of data input.We achieve this by running regular backups throughout the day, reducing the time window of potential data loss.Our Recovery Time Objective (RTO) is one hour.This is the maximum acceptable length of time that your system could be down following a failure or disruption.It represents our commitment to ensuring that your services are restored as quickly as possible.In the event of a disruption, our team will first evaluate the issue to determine the best course of action.If data recovery is necessary, we will restore from the most recent backup.We will then work to identify and resolve the root cause of the disruption to prevent a recurrence.Finally, we conduct regular test restores to ensure that our backup system is working as intended.These tests verify the integrity of the backup data and the functionality of the restore process.", "This documents an overview of the Argilla Cloud service - a comprehensive Software as a Service (SaaS) solution for data labeling and curation.The service is specifically designed to meet the needs of businesses seeking a reliable, secure, and user-friendly platform for data management.The key components of our service include advanced security measures, robust data backup and recovery protocols, flexible pricing options, and dedicated customer support.The onboarding process is efficient, enabling clients to start using the service within one business day.The scope of this proposal includes details on the aforementioned aspects, providing a clear understanding of the service offerings and associated processes.Argilla Cloud offers four plans:\n\nStarter: Ideal for teams initiating their journey in scaling data curation and labelling projects.Perfect for environments where production monitoring is not a requirement.Base: Tailored for teams seeking to amplify their data curation, labelling efforts, and model monitoring, with enhanced support from Argilla.Medium: Designed for teams expanding their language model pipelines, requiring robust ML lifecycle management fortified by Argilla's comprehensive support.Large: Geared towards teams heavily dependent on language model pipelines, human feedback, and applications, requiring complete ML lifecycle management with robust support.Scope of services Argilla Cloud, a fully managed SaaS, encompasses the following functionalities: Unrestricted Users, Datasets, and Workspaces: The service imposes no limits on the number of users, datasets, or workspaces, supporting scalability of operations.Role-Based Access Control: Administrators and annotators have differentiated access rights to ensure structured and secure data management.Custom Subdomain: Clients are provided with a distinct argilla.io subdomain for accessing the platform.Regular Updates and Upgrades: The service includes regular platform patches and upgrades as part of routine maintenance to uphold system integrity and security.Managed Service: Infrastructure maintenance, backend operations, and other technical aspects are managed by Argilla, eliminating the need for client-side management.Security The security framework of the Argilla Cloud service involves a multi-faceted approach: Data Encryption at Rest: Data stored within the system is encrypted, forming a crucial layer of security.This process automatically encrypts data prior to storage, guarding against unauthorized access.Network Security Measures: The infrastructure has been designed to prevent unauthorized intrusion and to ensure consistent service availability.Measures include firewall protections, intrusion detection systems, and scheduled vulnerability scans to detect and address potential threats.Role-Based Access Control: The system implements role-based access control, defining access levels based on user roles.This mechanism controls the extent of access to sensitive information, aligning it with the responsibilities of each role.Security Audits: Regular audits of security systems and protocols are conducted to detect potential vulnerabilities and verify adherence to security standards.Employee Training: All personnel receive regular security training, fostering an understanding of the latest threats and the importance of security best practices.Incident Response Protocol: In the case of a security incident, a pre-defined incident response plan is activated.This plan outlines the procedures for managing different types of security events, and aims to ensure swift mitigation of potential damage.In summary, the security measures in place include data encryption, network security protocols, role-based access control, regular audits, employee training, and a comprehensive incident response plan.These measures contribute to a secure environment for data management.Setup and onboarding The process for setup and onboarding for Argilla Cloud is designed to be efficient and straightforward.The procedure involves a sequence of steps to ensure a smooth transition and optimal use of the service.Step 1: Account Creation The setup process begins with the creation of the client owner account.We require the client to provide the following details: Full name of the administrator Preferred username Administrator's email address Once these details are received, we send an onboarding email to sign up.Step 2: Platform Orientation Once logged in, the administrator has full access to the Argilla Cloud platform.They can familiarize themselves with the platform interface and various features.If required, a guided tour or tutorial can be provided to walk the administrator through the platform.Step 3: User Management The administrator is then responsible for setting up additional user accounts.They can invite users via email, manage roles (admin, annotator, etc.), and assign access permissions to different workspaces and datasets.Step 4: Workspace and Dataset Configuration The administrator can create and manage multiple workspaces and datasets.They have the option to configure settings as per their team's requirements, including assigning datasets to specific workspaces and managing access permissions.Step 5: Training and Support Argilla provides open resources and support to aid in the onboarding process.This includes user manuals, tutorials, and access to our support team for any queries or issues that may arise during the setup and onboarding process.By following these steps, new users can be quickly onboarded and begin using the Argilla Cloud service with minimal downtime."]
Step 3:
Creating Argilla dataset and collecting feedback
Let us set up an Argilla Dataset for gathering human feedback. For fine-tuning, we need to set up a text question to gather the human written or edited responses. Also, leveraging on the multi-aspect feedback capabilities, we shall set up two additional feedback dimensions to rate how relevant the particular question is (irrelevant or bad quality responses might be generated since they are synthetic) and the quality of the context retrieved from our retriever component.
dataset = rg.FeedbackDataset(
fields=[rg.TextField(name="user-message"), rg.TextField(name="context")],
questions=[
rg.RatingQuestion(name="question-rating", title="Rate the relevance of the user question", values=[1,2,3,4,5], required=False),
rg.RatingQuestion(name="context-rating", title="Rate the quality and relevancy of context for the assistant", values=[1,2,3,4,5], required=False),
rg.TextQuestion(name="response", title="Write a helpful, harmless, accurate response to the user question"),
]
)We are using the questions, context, and generated responses to build our feedback records. We are prefilling the responses in the UI with OpenAI’s responses using suggestions and asking our labelers to edit them if necessary.
records = []
for question, answer, context in tqdm(zip(questions, answers, contexts), total=len(questions)):
# Instantiate the FeedbackRecord
feedback_record = rg.FeedbackRecord(
fields={"user-message": question, "context": "\n".join(context)},
suggestions=[
{
"question_name": "response",
"value": answer,
}
]
)
records.append(feedback_record)
# Publish dataset in Argilla UI
dataset = dataset.push_to_argilla(name="customer_assistant", workspace="admin")
dataset.add_records(records)This is how the Argilla UI looks like:

For the question above, we can select the relevance of the user questions as well as the quality of the context based on a scale of 1 to 5:

Step 4:
Preparing Argilla dataset for fine-tuning
We now read the responses from Argilla and prepare the dataset for fine-tuning following the fine-tuning format from OpenAI documentation.
We use the quick adaptation of LlamaIndex’s TEXT_QA_PROMPT system prompt and the fine-tuned responses from our Argilla dataset.
# Read the dataset from Argilla
dataset = rg.FeedbackDataset.from_argilla("customer_assistant", workspace="admin")# Adaptation from LlamaIndex's TEXT_QA_PROMPT_TMPL_MSGS[1].content
user_message_prompt ="""Context information is below.
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge but keeping your Argilla Cloud assistant style, answer the query.
Query: {query_str}
Answer:
"""
# Adaptation from LlamaIndex's TEXT_QA_SYSTEM_PROMPT
system_prompt = """You are an expert customer service assistant for the Argilla Cloud product that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like 'Based on the context, ...' or 'The context information ...' or anything along those lines.
"""Now, let us format it into a suitable structure:
def formatting_func(sample: dict) -> Union[Tuple[str, str, str, str], List[Tuple[str, str, str, str]]]:
from uuid import uuid4
if sample["response"]:
chat = str(uuid4())
user_message = user_message_prompt.format(context_str=sample["context"], query_str=sample["user-message"])
return [
(chat, "0", "system", system_prompt),
(chat, "1", "user", user_message),
(chat, "2", "assistant", sample["response"][0]["value"])
]
task = TrainingTask.for_chat_completion(formatting_func=formatting_func)Step 5:
Fine-tune GPT3.5 with high-quality feedback
We now fine-tune gpt-3.5-turbo with the exported dataset using the Argilla Trainer.
trainer = ArgillaTrainer(
dataset=dataset,
task=task,
framework="openai",
)
trainer.train(output_dir="my-ft-openai-model")Step 6:
Evaluating base versus fine-tuned with human preferred data
We've established a new feedback dataset to assess the fine-tuned model against the base model, utilizing the test dataset.
Various methods can be employed for collecting feedback, but for this scenario, the most appropriate approach involves gathering human preference data regarding responses from the two models. This will be achieved by utilizing Argilla's RankingQuestion, where labelers rank responses based on accuracy and helpfulness.
Furthermore, to address instances where both responses may be equally unsatisfactory, labelers will be asked to provide a correct response, contributing demonstration data for incorporation into the fine-tuning process.
Create dataset and collect feedback
We set up and publish a new dataset with a RankingQuestion and TextQuestion, showing our labelers the user-message and two responses (from the base and the fine-tuned models).
dataset = rg.FeedbackDataset(
fields=[rg.TextField(name="user-message"), rg.TextField(name="response-a"), rg.TextField(name="response-b")],
questions=[
rg.RankingQuestion(name="preference", title="Which response is more helpful, harmless, and accurate.", values=["response-a", "response-b"]),
rg.TextQuestion(name="response", title="If none is good, write a helpful, harmless, accurate response to the user question", required=False),
]
)# Read our test questions
questions = load_dataset("argilla/cloud_assistant_questions", split="test")["question"]Now, we shall generate responses from the base model:
# Base model
index = VectorStoreIndex.from_documents(documents, service_context=gpt_35_context)
query_engine = index.as_query_engine(similarity_top_k=2)
contexts = []
base_model_responses = []
for question in tqdm(questions):
response = query_engine.query(question)
base_model_responses.append(str(response))Here is the fine-tuned model generation of responses:
# Ft model: replace with the id of your ft model
ft_context = ServiceContext.from_defaults(
llm=OpenAI(model="ft:gpt-3.5-turbo-...", temperature=0.3)
)
index = VectorStoreIndex.from_documents(documents, service_context=ft_context)
query_engine = index.as_query_engine(similarity_top_k=2)
contexts = []
ft_model_responses = []
for question in tqdm(questions):
response = query_engine.query(question)
ft_model_responses.append(str(response))To mitigate potential biases such as labelers consistently choosing a specific position or revealing the presence of two distinct models, we opt for randomizing the position of the fine-tuned model's response.
Two metadata fields, indicating whether response-a and response-b are from the base or fine-tuned model, will be retained. During response collection, this metadata will be utilized to correlate the ranking with each respective model.
records = []
for base, ft, question in zip(base_model_responses, ft_model_responses, questions):
# Randomizing the position is a highly important step to mitigate labeler biases
# Shuffle the order of base and ft
response_a, response_b = random.sample([base, ft], 2)
# Map the responses back to their model names
models = {
base: "base_model",
ft: "ft_model"
}
feedback_record = rg.FeedbackRecord(
fields={"user-message": question, "response-a": response_a, "response-b": response_b},
metadata={"response-a-model": models[response_a], "response-b-model": models[response_b]}
)
records.append(feedback_record)
dataset = dataset.push_to_argilla(name="finetuned-vs-base-preference", workspace="admin")
dataset.add_records(records)Collecting feedback from Argilla UI:
Choice 1:

Choice 2:

Choice 3:

Step 7:
Retrieval & analysis of responses
We have the capability to dynamically gather responses from our labelers. Through this process, we calculate the win rate and ties, considering instances where users indicate that both responses are equally satisfactory or unsatisfactory.
In a limited evaluation set, we observe that the fine-tuned model responses are favored approximately 60% of the time, triple the preference for the base model. Additionally, both responses are deemed equally good or bad around 20% of the time.
Even with a modest fine-tuning and evaluation dataset, these early findings demonstrate the potential advantages of fine-tuning models in improving RAG systems.

Community
Argilla provides extensive documentation right from their tutorials for both beginners and advanced levels to integrations with LangChain, FastAPI, sentence-transformers etc.
Given the open-source nature of this platform, they enthusiastically embrace and encourage new contributions and ideas. You're invited to engage with the community by joining their Slack channel or making contributions to their Github repository!
Also, they offer valuable content on their YouTube channel, and for developers and contributors, comprehensive documentation is readily available.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}