
Generating Synthetic Text2SQL Instruction Dataset to Fine-tune Code LLMs
Creating text2SQL data with defined roles, and sub-topics guiding natural language question generation using GPT-4.

Large Language Models (LLMs) have unlocked a plethora of possibilities, from automating routine tasks to assisting in software development. These powerful models can be fine-tuned to excel at specific tasks by training them on relevant datasets. For instance, CodeLLMs used for writing or assisting with coding require extensive training on vast amounts of human-written code.
The fine-tuning process involves exposing the LLMs to a curated dataset containing examples of the desired task or output. Various deep-learning techniques are applied, through which the model learns patterns and generates relevant and coherent responses when presented with new inputs. However, curating high-quality datasets and fine-tuning LLMs effectively remains a challenge.
The Problem
Suppose we need to train a CodeLLM that can effectively translate natural language business questions to SQL queries on a table. However, no readily available datasets are specifically designed for this task. Where suitable datasets are scarce, how can we train our model effectively in such cases?
The Solution
Synthetic data offers a viable solution to this problem. This process involves using a more powerful and larger language model to create a dataset tailored for fine-tuning a smaller or more specialized model. Synthetic data generation gained significant attention with Stanford researchers' introduction of the Self-Instruct framework Self-Instruct in late 2022.
Since then, there has been a surge in the development of powerful language models, such as GPT-4, Llama-2, Claude, and Mixtral, among others. These cutting-edge models have demonstrated outstanding performance across diverse tasks making them suitable for synthetic data generation.
Generating Synthetic SQL Fine-tuning Dataset
Various techniques have been used before to translate natural language questions to SQL queries, with one of the earliest attempts (IBM's RENDEZVOUS system) in the late 1970s! Many other attempts in the past decade used seq-to-seq techniques — SQLNet, type-aware encoder-decoder architecture — TypeSQL, relation-aware self-attention mechanism — RAT-SQL, among others.
With the advent of LLMs, the attention has turned towards these models. The approach to generate NL2SQL has mostly involved fine-tuning language models with instruction datasets containing natural language and SQL query pairs. The most recent and successful attempt is the SQLCoder2 by defog.ai.
In this blog post, we will create a simple pipeline to create a QnA dataset having "Business question"-"SQL query" pairs using the Google Play Store Apps dataset. We will use GPT-4 for this task because of its excellent coding capabilities compared to other LLMs.
Setting Up the Pre-requisites
We need a PostgreSQL database to run the SQL queries on. So, let's first get on with that.
1. PostgreSQL
If you don't yet have Docker installed on your system, follow the instructions here and download it.
Pull the PostgreSQL Docker image.
docker pull postgresRun the PostgreSQL Docker container.
docker run --name my-postgres -e POSTGRES_PASSWORD=mysecretpassword -p 5432:5432 -d postgresThis command does the following:
--name my-postgres: Assign a name to the container-e POSTGRES_PASSWORD=mysecretpassword: Sets the password for thepostgresuser (replacemysecretpasswordwith your desired password)-p 5432:5432: Maps the container's PostgreSQL port (5432) to the same port on the host machine-d: Runs the container in detached mode (in the background)postgres: The name of the Docker image to run
We should now create a database to work with the table having our data.
First, connect to the PostgreSQL container's shell.
docker exec -it my-postgres bash
Once inside the container's shell, you can connect to the server using the psql command.
psql -u postgresThis will connect you to the PostgreSQL server as the postgres user.
After connecting to the PostgreSQL server, you can create a new database using the CREATE DATABASE command.
CREATE DATABASE mydatabase;
You should see a message confirming that the database was created successfully.
Exit the PostgreSQL shell.
\qAnd exit the container's shell.
exitAnd you are good to go for the rest of the tutorial!
2. Environment Prep
First, download the Google PlayStore apps CSV file from here.
Create and navigate to your project directory. Then, create a Python environment for this project and activate it (modify the commands based on your OS).
python -m venv venv && source ./venv/bin/activateInstall all the required packages.
pip install pandas psycopg sqlalchemy tabulate openai python-dotenvThe next step is to create a .env file and then add OPENAI_API_KEY=<your-openai-api-key>.
Now, fire up a Jupyter notebook inside your newly created venv and do all the necessary imports.
import psycopg
from psycopg.rows import dict_row
import pandas as pd
from sqlalchemy import create_engine
from openai import OpenAI
from tabulate import tabulate
import json
from itertools import islice
import pickle
from dotenv import load_dotenv
load_dotenv()
client = OpenAI()3. Dataset Prep
# follow the format: postgresql+psycopg://user:password@host:port/dbname
engine = create_engine('postgresql+psycopg://postgres:postgres@localhost:5432/googleplaystore')
df = pd.read_csv("./googleplaystore.csv")
df.columns = [col.replace(" ", "_").lower() for col in df.columns]
# this weird date was causing an error while running one of the sql queries
i = df[df['last_updated'] == "1.0.19"].index
df.drop(i, inplace=True)
df.to_sql(name='playstoreapps', con=engine, if_exists='replace')This code snippet connects to a PostgreSQL database using SQLAlchemy and reads a CSV file into a pandas DataFrame. The column names are renamed to adhere to PostgreSQL best practices by changing the column names to start with a lowercase letter and replacing whitespace with an underscore. There was one problematic row while I was experimenting. That row is removed manually. We then create a table from this DataFrame.
We can execute a PostgreSQL command and see if our setup works as intended.
# `dict_row` ensures that rows are represented as dictionaries with column names as keys
# https://www.psycopg.org/psycopg3/docs/api/rows.html
conn = psycopg.connect("postgresql://postgres:postgres@localhost:5432/googleplaystore", row_factory=dict_row)
conn.adapters.register_loader("numeric", psycopg.types.numeric.FloatLoader)with conn.cursor() as cur:
cur.execute("""
SELECT categor
""")
res = cur.fetchall()Generating the Dataset
Let's first look at how our dataset should look. Here's an example:
{
"question": "What are the top 5 categories with the highest average rating?",
"sql_query": "SELECT category, AVG(rating) AS average_rating FROM playstoreapps GROUP BY category ORDER BY average_rating DESC LIMIT 5;"
}Now, we could pass in the table schema and ask GPT-4 to generate questions and answers. However, this approach is inefficient and can lead to inaccurate SQL queries.
Hence, we will define a set of roles, and get a few sub-topics for each of the roles from which the questions will be generated.
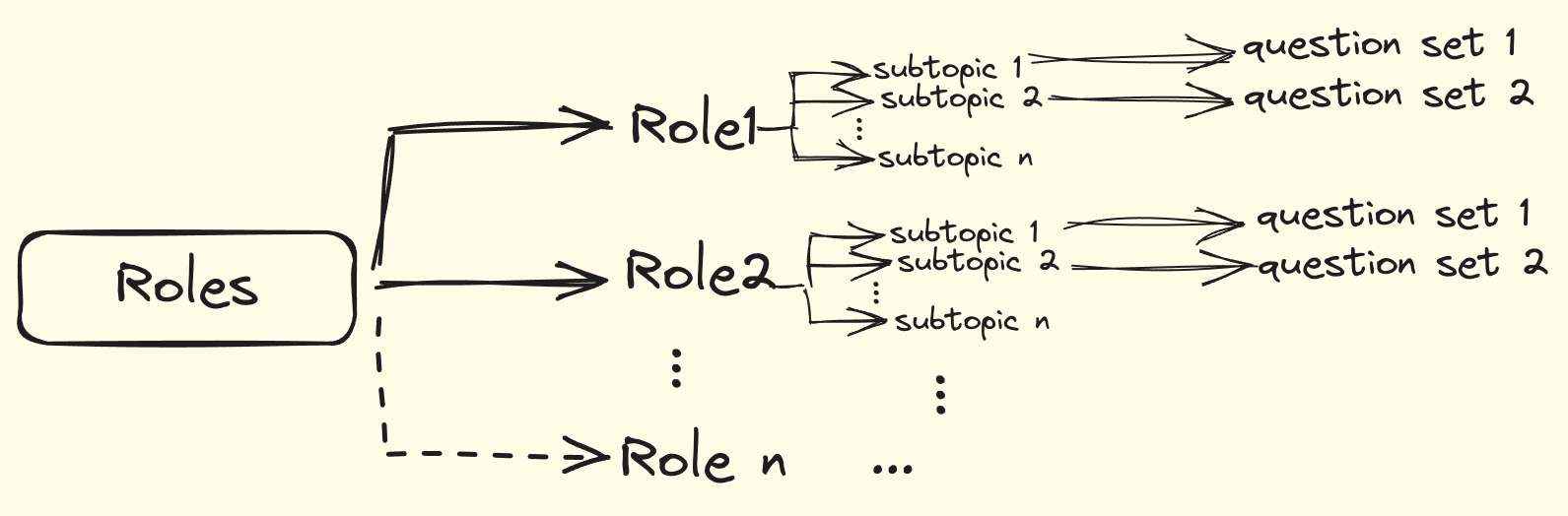
1. Getting Sub-Topics
# defined by the user
ROLES = ["VP of Business", "Product Manager"]
# getting the table schema
with conn.cursor() as cur:
cur.execute("""
SELECT column_name, data_type FROM information_schema.columns WHERE table_name = 'playstoreapps';
""")
res = cur.fetchall()
def create_table_script(table_name: str, table_schema: list[dict]) -> str:
"""
table_schema: list[str] - output of "SELECT column_name, data_type FROM information_schema.columns WHERE table_name = 'playstoreapps';"
with `row_factory` parameter set to `dict_row` in psycopg's `cursor.execute()` function.
Returns a create table script string.
"""
create_script = f"CREATE TABLE {table_name} (\n"
for column in table_schema:
create_script += f" {column['column_name']} {column['data_type'].upper()},\n"
create_script += ");"
return create_script
TABLE_SCHEMA = create_table_script("playstoreapps", res)
print(TABLE_SCHEMA)CREATE TABLE playstoreapps
index BIGINT,
app TEXT,
category TEXT,
rating DOUBLE PRECISION,
reviews TEXT,
size TEXT,
installs TEXT,
type TEXT,
price TEXT,
content_rating TEXT,
genres TEXT,
last_updated TEXT,
current_ver TEXT,
android_ver TEXT,
);The create_table_script function takes in the output of the query SELECT column_name, data_type FROM information_schema.columns WHERE table_name = 'playstoreapps'; and generates a table creation script using simple string manipulation.
With the roles and table schema defined, we can now generate the questions shown in the figure above.
Let's define a function that gets the sub-topics to guide the question generation given a role and the table schema. We use a seed parameter to get deterministic outputs every time the code is run. Using JSON mode makes the model output in JSON format which is easy to work with.
Notice how we have used ### and ``` to enclose and separate different prompt elements. Refer to this article for OpenAI-recommended prompt engineering tips.
def get_sub_topics_from_schema(table_schema: str, roles: list[str], num_sub_topics: int = 5, temperature: float = 0.2, seed: int = 42) -> list:
"""Returns a list of topics for each role."""
system_prompt = """You are a senior and expert Business Analyst who can come up with relevant topics according to the provided instructions."""
message_prompt = f"""\
Following is a schema of a PostgresSQL table.
```
{table_schema}
```
Instruction:###
Provide {num_sub_topics} key sub-topics or areas from which important business questions can be asked by a [{", ".join(role for role in roles)}] based on the \
information provided in the table whose schema is given.
Provide the sub-topics with role names as keys in JSON format.
###
"""
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": message_prompt}
],
response_format={"type": "json_object"},
temperature=temperature,
seed=seed,
)
response_dict = json.loads(completion.choices[0].message.content)
return response_dictsub_topics = get_sub_topics_from_schema(TABLE_SCHEMA, ROLES)
print(sub_topics){'VP of Business': ['Market Segmentation Analysis',
'Competitor Analysis',
'Pricing Strategy Evaluation',
'User Engagement Metrics',
'Market Trends and Forecasting'],
'Product Manager': ['Feature Prioritization based on User Reviews',
'App Performance Monitoring',
'Version Update Impact Analysis',
'Content Rating Compliance',
'Platform Compatibility Assessment']}2. Getting Business Questions
We use a similar prompt as before, but this time we also unpack the sub-topic values in a list fashion.
get_questions_from_sub_topics(table_schema: str, role: str, sub_topics: list[str]) -> dict[list]:
"""Returns a dict with keys as subtopics and values as questions."""
question_system_prompt = f"""You are an expert {role}. Accordingly follow the given instructions."""
question_message_prompt = f"""\
Following is a PostgresSQL table schema:
```
{table_schema}
```
Instructions:###
Generate 10 business questions for each of the sub-topics or areas that follow: \
[{", ".join(topic for topic in sub_topics)}].
The questions must be answerable using SQL queries from the information present in the table whose schema is given.
Provide the output in JSON format with sub-topics as keys.
###
"""
completion = client.chat.completions.create(
model="gpt-4-turbo-preview",
messages=[
{"role": "system", "content": question_system_prompt},
{"role": "user", "content": question_message_prompt}
],
response_format={"type": "json_object"},
temperature=0.2,
seed=42
)
response_dict = json.loads(completion.choices[0].message.content)
return response_dictThe function defined above takes in a role and the sub-topics. The role is inserted into the system prompt to guide the question generation according to that role.
questions_dict = {}
for role in ROLES:
questions_dict.update(get_questions_from_sub_topics(TABLE_SCHEMA, role, sub_topics[role]))
print(questions_dict)
questions = []
for sub_topic in questions_dict.keys():
questions.extend(questions_dict[sub_topic])
print(questions[:5]){'Market Segmentation Analysis': ['What are the top 5 categories with the highest average rating?',
'How many apps are there in each category?',
'What is the average number of installs per category?',
"Which categories have the most 'Free' vs 'Paid' apps?",
"What is the distribution of apps based on 'Content Rating' in each category?",
"How does the average app rating vary across different 'Content Ratings'?",
'Which genres are most popular in terms of number of apps?',
'What is the average size of apps in each category?',
'How many apps have been updated in the last year, categorized by their category?',
'What are the top 5 categories with the highest number of reviews?'],
'Pricing Strategy Evaluation': ['What is the average price of apps in each category?',
'How many apps are priced above $5 in each category?',
'What is the correlation between price and rating for paid apps?',
"How does the average price of apps vary across different 'Content Ratings'?",...}['What are the top 5 categories with the highest average rating?',
'How many apps are there in each category?',
'What is the average number of installs per category?',
"Which categories have the most 'Free' vs 'Paid' apps?",
"What is the distribution of apps based on 'Content Rating' in each category?"]3. Generating SQL Queries for Business Questions
Let's define another function that takes in the business questions and the table schema, and generates the SQL queries to answer those questions. We will set the temperature parameter to 0.1 for a more technical task like this. Feel free to experiment with the temperature for business questions and SQL query generation to see what works best.
# helper function to unpack questions in SQL query generation prompt
def unpack_questions(questions: list[str]) -> str:
"""Returns a string with each list element numbered and separated by new line."""
out = ""
for i, question in enumerate(questions):
out += f"{i + 1}. {question}\n"
return outdef get_sql_query(table_schema: str, questions: list[str]) -> dict[list]:
"""Returns SQL queries given business questions."""
sql_system_prompt = """You are an SQL expert who can follow instructions and accurately provide appropriate SQL queries to business questions."""
sql_message_prompt = f"""\
Following is a PostgreSQL table schema:
```
{table_schema}
```
Instructions:###
Your job is to write SQL queries given the table schema to answer the given business questions as best as possible.
Provide the output in JSON format with one key "sql_queries" and the SQL queries in a list in the same order as the business questions.
###
Following are business questions with different questions separated by newline. Business questions:###
{utils.unpack_questions(questions)}###
"""
completion = client.chat.completions.create(
model="gpt-4-turbo-preview",
messages=[
{"role": "system", "content": sql_system_prompt},
{"role": "user", "content": sql_message_prompt}
],
response_format={"type": "json_object"},
temperature=0.1,
seed=42
)
response_dict = json.loads(completion.choices[0].message.content)
return response_dictHere, we are passing 10 questions in one call to the model. This again, can be chosen experimentally based on how correct the generated SQL queries are. Later, we will build an evaluation pipeline that evaluates and corrects incorrect queries.
q_it = iter(questions)
sql_queries = []
for i in range(10):
print(f"Generating SQL queries for question set {i+1}/10")
sql_queries.extend(
get_sql_query(TABLE_SCHEMA, list(islice(q_it, 10)))['sql_queries']
)
print(sql_queries[:5])['SELECT category, AVG(rating) AS average_rating FROM playstoreapps GROUP BY category ORDER BY average_rating DESC LIMIT 5;',
'SELECT category, COUNT(*) AS total_apps FROM playstoreapps GROUP BY category;',
"SELECT category, AVG(CAST(REPLACE(installs, '+', '') AS BIGINT)) AS average_installs FROM playstoreapps GROUP BY category;",
"SELECT category, COUNT(*) FILTER (WHERE type = 'Free') AS free_apps, COUNT(*) FILTER (WHERE type = 'Paid') AS paid_apps FROM playstoreapps GROUP BY category ORDER BY free_apps DESC, paid_apps DESC;",
'SELECT category, content_rating, COUNT(*) AS total_apps FROM playstoreapps GROUP BY category, content_rating;']The above code snippet first creates a Python iterator object from the list of questions. Using islice from Python's in-built library itertools,, we then iterate over 10 questions at a time using islice(q_it, 10).
Evaluating the Generated SQL Queries
This process can be made more robust by running the SQL queries and fixing them if there are any errors. To do that, we will define two functions. One that runs the SQL query, catches the exception (if one is thrown) and calls the second function to fix it. The second function will prompt GPT-4 with the table schema, the business question, the SQL query, and the exception to fix it.
def fix_sql_query(sql_query: str, exception: str, question: str, table_schema: str):
print("Retrying...\n")
system_prompt = "You are an SQL expert, who can debug and write SQL queries accurately."
message_prompt = f"""\
Following is a PostgreSQL table schema:
```
{table_schema}
```
Instructions:###
You are given a business question, the corresponding SQL query that answers the question from the given table schema and an exception or hint caused by executing the SQL query.def
Identify what might be the error and rewrite the SQL query. Provide output in JSON format with "sql_query" as the key.
###
Business question:###
{question}
###
SQL query:###
{sql_query}
###
Exception or hint:###
{exception}
###
"""
completion = client.chat.completions.create(
model="gpt-4-turbo-preview",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": message_prompt}
],
response_format={"type": "json_object"},
temperature=0.2,
seed=42
)
response_dict = json.loads(completion.choices[0].message.content)
return response_dict['sql_query']def get_query_output(query: str, index_num: int, question: str):
global conn
global sql_queries
attempt = 0
retry_count = 2
query_temp = query
while attempt < retry_count:
res = None
try:
with conn.cursor() as cur:
cur.execute(query)
res = cur.fetchall()
break
except Exception as e:
print(f"Exception: '{e}' occured in iteration {index_num}")
conn = psycopg.connect("postgresql://postgres:postgres@localhost:5432/googleplaystore", row_factory=dict_row)
conn.adapters.register_loader("numeric", psycopg.types.numeric.FloatLoader)
if res is None:
res = ""
attempt += 1
if attempt < retry_count:
new_query = fix_sql_query(query, e, question, TABLE_SCHEMA)
query = new_query
sql_query[index_num] = new_query
else:
print(f"Couldn't fix SQL query at index {index_num}")
sql_query[index_num] = query_temp
# convert output to markdown
md_res = tabulate(res, headers="keys", tablefmt="pipe")
return md_resThe get_query_output function executes the given query. If an exception is raised, the query is re-executed (here) 1 time after calling the fix_sql_query function with the query and the exception.
If the query is fixed, the corresponding element in the sql_queries list is updated. Let us see this in action.
md_outs = []
for i,sql_query in enumerate(sql_queries):
md_outs.append(get_query_output(sql_query, i, questions[i]))Output messages
Exception: 'invalid input syntax for type bigint: "10,000"' occured in iteration 2
Retrying...
Exception: 'operator does not exist: text >= timestamp without time zone
LINE 1: ...d_last_year FROM playstoreapps WHERE last_updated >= (CURREN...
^
HINT: No operator matches the given name and argument types. You might need to add explicit type casts.' occured in iteration 8
Retrying...
Exception: 'invalid input syntax for type bigint: "10,000+"' occured in iteration 25
Retrying...
Exception: 'invalid input syntax for type bigint: "10,000"' occured in iteration 25
Couldn't fix SQL query at iteration 25
Exception: 'operator does not exist: text < timestamp without time zone
LINE 1: ...apps WHERE category = 'Business' AND last_updated < (CURRENT...
^
HINT: No operator matches the given name and argument types. You might need to add explicit type casts.' occured in iteration 26
Retrying...
Exception: 'invalid input syntax for type double precision: "19M"' occured in iteration 27
Retrying...
Exception: 'invalid input syntax for type bigint: "100,000"' occured in iteration 40
Retrying...
Exception: 'operator does not exist: text < timestamp with time zone
LINE 1: ...laystoreapps WHERE type = 'Paid' AND last_updated < NOW() - ...
^
HINT: No operator matches the given name and argument types. You might need to add explicit type casts.' occured in iteration 42
Retrying...
Exception: 'invalid input syntax for type bigint: "100,000"' occured in iteration 44
Retrying...
Exception: 'operator does not exist: text >= timestamp with time zone
LINE 1: ...laystoreapps WHERE type = 'Paid' AND last_updated BETWEEN NO...
^
HINT: No operator matches the given name and argument types. You might need to add explicit type casts.' occured in iteration 45
Retrying...
Exception: 'invalid value "ch" for "DD"
DETAIL: Value must be an integer.' occured in iteration 45
Couldn't fix SQL query at iteration 45
Exception: 'invalid input syntax for type bigint: "100,000"' occured in iteration 46
Retrying...
Exception: 'invalid input syntax for type double precision: ""' occured in iteration 47
Retrying...
Exception: 'invalid input syntax for type bigint: "100,000"' occured in iteration 48
Retrying...
Exception: 'invalid input syntax for type bigint: "100,000"' occured in iteration 49
Retrying...
Exception: 'operator does not exist: text < timestamp without time zone
LINE 1: ...CT COUNT(*) FROM playstoreapps WHERE last_updated < (CURRENT...
^
HINT: No operator matches the given name and argument types. You might need to add explicit type casts.' occured in iteration 61
Retrying...
Exception: 'invalid value "Ja" for "DD"
DETAIL: Value must be an integer.' occured in iteration 61
Couldn't fix SQL query at iteration 61
Exception: 'invalid input syntax for type double precision: "Varies with device"' occured in iteration 62
Retrying...
Exception: 'invalid input syntax for type bigint: "10,000+"' occured in iteration 64
Retrying...
Exception: 'invalid input syntax for type bigint: "10,000"' occured in iteration 64
Couldn't fix SQL query at iteration 64
Exception: 'invalid input syntax for type bigint: "10,000+"' occured in iteration 65
Retrying...
Exception: 'invalid input syntax for type bigint: "10,000"' occured in iteration 65
Couldn't fix SQL query at iteration 65
Exception: 'invalid input syntax for type bigint: "500,000+"' occured in iteration 68
Retrying...
Exception: 'invalid input syntax for type bigint: "500000+"' occured in iteration 68
Couldn't fix SQL query at iteration 68
Exception: 'operator does not exist: text >= timestamp with time zone
LINE 1: ...CT COUNT(*) FROM playstoreapps WHERE last_updated >= NOW() -...
^
HINT: No operator matches the given name and argument types. You might need to add explicit type casts.' occured in iteration 86
Retrying...
Exception: 'invalid value "Ja" for "DD"
DETAIL: Value must be an integer.' occured in iteration 86
Couldn't fix SQL query at iteration 86
Exception: 'invalid input syntax for type bigint: "10,000"' occured in iteration 88
Retrying...
Exception: 'operator does not exist: text >= timestamp without time zone
LINE 1: ...ps WHERE content_rating = 'Teen' AND last_updated >= (CURREN...
^
HINT: No operator matches the given name and argument types. You might need to add explicit type casts.' occured in iteration 96
Retrying...
Exception: 'invalid input syntax for type double precision: ""' occured in iteration 99
Retrying...
Initially, 22 queries caused exceptions, but now 10 queries were fixed by GPT-4. And of course, you can use a retry count higher than 2 to fix more queries.
count = 0
for m in md_outs:
if m == '':
count += 1
print(count)12final_sql_queries = []
final_questions = []
for i,sq in enumerate(zip(sql_queries, questions)):
if md_outs[i] != '':
final_sql_queries.append(sq[0])
final_questions.append(sq[1])That concludes our data generation process. The last step left is to write this data into a file to be usable. We'll use the JSONL format here.
table_schema = "CREATE TABLE playstoreapps index BIGINT, app TEXT, category TEXT, rating DOUBLE PRECISION, reviews TEXT, size TEXT, installs TEXT, type TEXT, price TEXT, content_rating TEXT, genres TEXT, last_updated TEXT, current_ver TEXT, android_ver TEXT);"
# Create the JSONL file
with open("dataset.jsonl", "w") as f:
for question, sql_query in zip(final_questions, final_sql_queries):
data = {
"table_schema": table_schema,
"question": question,
"sql_query": sql_query
}
json_data = json.dumps(data)
f.write(json_data + "\n")You can download the dataset here:
Conclusion
In this blog post, we explored an approach to generating synthetic text2SQL data for fine-tuning Language Models (LMs). By leveraging the excellent coding capabilities of GPT-4, we successfully created a dataset of business questions and their corresponding SQL queries.
The key steps included defining relevant roles, getting subtopics based on the given database schema, generating natural language business questions based on the sub-topics aligned with specific roles, and finally, producing SQL queries to answer those questions. Throughout, we witnessed GPT-4's impressive performance and its potential in synthetic data generation use cases.
While the initial SQL queries contained some errors, we implemented an evaluation pipeline that identified and fixed these issues using GPT-4's debugging capabilities. This iterative process not only improved the quality of the dataset but also highlighted the potential for Language Models to self-correct and refine their outputs.
The resulting dataset from this — or a similar — approach can serve as a valuable resource for fine-tuning smaller or more specialized Language Models for NL2SQL purposes.
In conclusion, an important note I want to add is that in this post we have used a single table throughout. It would be an interesting experiment to try and generate a dataset using the same or a similar approach over multiple tables, trying to get complex SQL queries with joins, CTEs, etc.
Thank you for reading this blog.
You might find this blog post that explores creating E-Commerce data having real-world like data distribution interesting:
 Ninaad P S
Ninaad P S