
Serializability in Spark: Using Non-Serializable Objects in Spark Transformations
Discover strategies to effectively harness Spark's distributed computing power when working with third-party or custom library objects that aren't serializable.

Watching Spark distribute our data-crunching tasks across multiple machines with great speed is indeed delightful. However, debugging issues that arise from the powerful abstractions it provides can be less enjoyable.
The Problem
I was working on extracting IPs and their hostnames from WARC files. These IPs were then enriched with information from the MaxMind GeoIP2 database.
Here's a condensed code snippet of how I was trying to achieve it.
import geoip2
from pyspark.sql.functions import udf
from pyspark.sql.types import (
StructType,
StructField,
StringType,
...
)
reader = geoip2.database.Reader('/path/to/GeoLite2-City.mmdb')
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("maxmind-warc") \
.getOrCreate()
warciphost_df = ...
ip_info_schema = StructType([
StructField("is_anonymous_proxy", BooleanType(), True),
...
])
def get_ip_info(ip):
response = reader.city(ip)
return (
response.traits.is_anonymous_proxy,
response.traits.is_satellite_provider,
response.traits.is_hosting_provider,
response.postal.code,
...
)
get_ip_info_udf = udf(get_ip_info, ip_info_schema)
result_df = warciphost_df.withColumn("ip_info", get_ip_info_udf("ip"))
final_df = result_df.select("ip", "ip_info.*")
This looks fine. However, I overlooked a crucial aspect of Spark.
Serializing in Spark
In a nutshell, Spark distributes or splits a given task across many machines and processes it in parallel. The task is sent to the Spark Master from the driver program (the Python script or the JLab notebook). The master then decides how to distribute the task across the machines.
map(), join(), filter(), count(), reduce(), collect(), etc., distribute computation across the cluster. Here, I am using a UDF (user-defined function) which can also distributed.You can read more about it here.
Our setup consists of 5 workers and 1 master. The get_ip_info function will be executed across different workers. How does this happen though? The function and variables inside are sent to the worker nodes as a byte stream (since they are connected over a network). This is achieved through serialization (using pickle by default). This is an integral concept of distributed computing. You can read more about what is serialized here.
This is where the problem is. Spark tries to pickle everything in the UDF, including the reader object, which it cannot.
Custom Serializable Reader
How can we overcome this? We have to make our UDF completely "pickleable". For that, we'll have to write a small wrapper around our reader object.
class SerializableReader:
def __init__(self, db_path):
self.db_path = db_path
self.reader = None
def __getstate__(self):
return {'db_path': self.db_path}
def __setstate__(self, state):
self.db_path = state['db_path']
self.reader = None
def get_reader(self):
if self.reader is None:
self.reader = geoip2.database.Reader(self.db_path)
return self.reader
This looks cryptic at first glance. I'll break it down step by step.
The __getstate__ method is called when an object is being pickled. All I'm doing here is skipping the pickling of the reader object entirely and only pickling db_path instead.
Likewise, the __setstate__ method is called when an object is being unpickled. It is used to restore the object's state from the pickle. It receives the dictionary returned by __getstate__ which can be used to restore the object's state. Here we restore db_path but initialize reader to None.
Another method get_reader is used to "lazily" create the reader object if it isn't there already. We do this because creating a reader object is expensive according to the GeoIP2 docs.
Putting It All Together: The Solution
Cool. We have solved serialization. What next? Now, here's one way we could modify the get_ip_info function.
s_reader = SerializableReader('/path/to/GeoLite2-City.mmdb')
reader = s_reader.get_reader()
def get_ip_info(ip):
response = reader.city(ip)
return (
response.traits.is_anonymous_proxy,
response.traits.is_satellite_provider,
response.traits.is_hosting_provider,
response.postal.code,
...
)
This should work, right?
There's a little caveat we need to pay attention to here. The reader object is only available in the driver program (in my case, a Jupyter Lab interface). The UDF get_ip_info is processed on multiple worker nodes where the reader object is required.
We can solve this issue by "broadcasting" the SerializableReader object to all the workers. Here's how we can do that.
reader_broadcast = spark.sparkContext.broadcast(SerializableReader("path/to/GeoLite2-City.mmdb")
def get_ip_info(ip):
reader = reader_broadcast.value.get_reader()
response = reader.city(ip)
return (
response.traits.is_anonymous_proxy,
response.traits.is_satellite_provider,
response.traits.is_hosting_provider,
response.postal.code,
...
)
What's happening here is that a copy of an object of SerializableReader is being sent to all the worker nodes. The line reader_broadcast.value.get_reader() accesses the object in the worker node where the UDF is being executed in.
The reader object is created only if it has not already been created in the SerializableReader object in that worker.
Here's the full code for reference.
import geoip2
from pyspark.sql.functions import udf
from pyspark.sql.types import (
StructType,
StructField,
StringType,
...
)
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("maxmind-warc") \
.getOrCreate()
warciphost_df = ...
class SerializableReader:
def __init__(self, db_path):
self.db_path = db_path
self.reader = None
def __getstate__(self):
return {'db_path': self.db_path}
def __setstate__(self, state):
self.db_path = state['db_path']
self.reader = None
def get_reader(self):
if self.reader is None:
self.reader = geoip2.database.Reader(self.db_path)
return self.reader
reader_broadcast = spark.sparkContext.broadcast(SerializableReader("path/to/GeoLite2-City.mmdb")
ip_info_schema = StructType([
StructField("is_anonymous_proxy", BooleanType(), True),
StructField("is_satellite_provider", BooleanType(), True),
StructField("is_hosting_provider", BooleanType(), True),
...
])
def get_ip_info(ip):
reader = reader_broadcast.value.get_reader()
response = reader.city(ip)
return (
response.traits.is_anonymous_proxy,
response.traits.is_satellite_provider,
response.traits.is_hosting_provider,
...
)
get_ip_info_udf = udf(get_ip_info, ip_info_schema)
result_df = warciphost_df.withColumn("ip_info", get_ip_info_udf("ip"))
final_df = result_df.select("ip", "ip_info.*")
Phew! That was a lot to digest. Let's look at where the IPs in the WARC files come from.
Some Visualizations!
I have run this on a random sample of 10 WARC files taken from the July 2024 Common-Crawl dump while enriching it with the MaxMind database (20 August 2024 version).
Here are some plots showcasing the same.
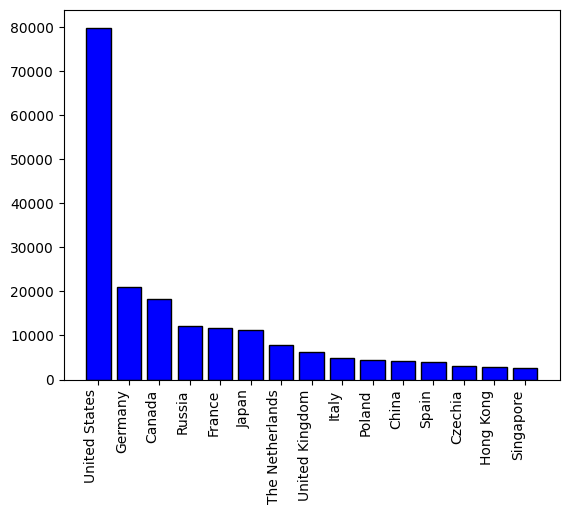
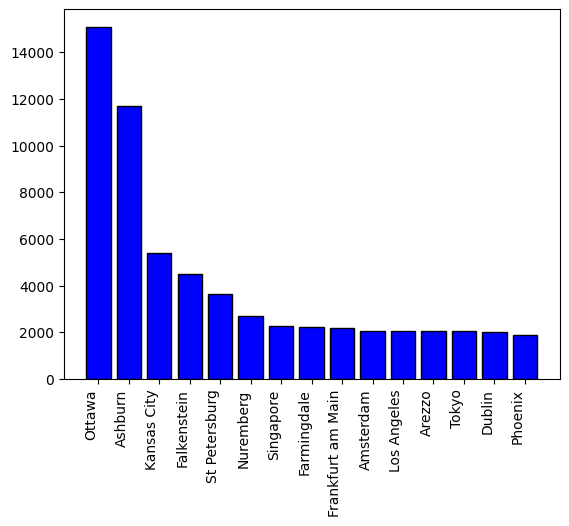
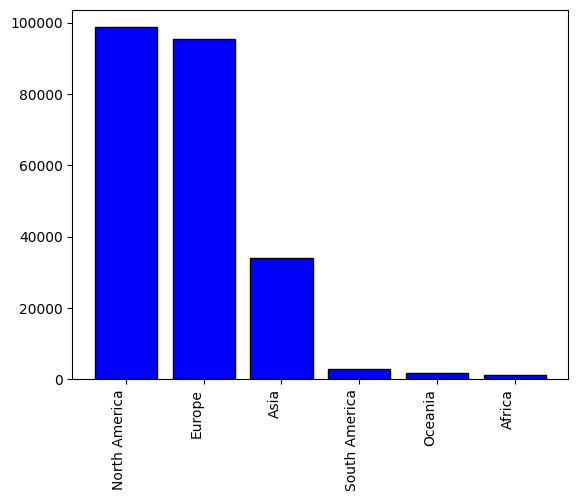
Conclusion
That brings us to the end of this blog. We glanced at how tasks are distributed in Spark and sent to the worker nodes. We saw how and why serializability issues can pop up in Spark and solved them by implementing a custom wrapper class around the un-serializable object in our code. This serializable object was then broadcasted to the worker nodes to be accessible in the serialized code run on them.
We then concluded with some statistics on the IPs' distribution in a sample of processed WARC files.


