
Postgres text similarity with commoncrawl domains

Commoncrawl is a public repository of web crawl data made available for analysis. In this post I want to extract the list of domains crawled, stick them into a Postgres database and play with text similarity functions provided by pg_similarity extension.
The basic steps to be followed are;
1. Get the index files in parquet format - A collection of parquet files are published that contain the URLs crawled and other related metadata. The latest one at the time of writing this post is available in the S3 location here.
Download any random file from the list of parquet files.
2. Read parquet file in Pandas - This isn't ideal if you would like to analyze all the files. My intention here is to look at maybe one or two files. If you want to analyze all of it, follow this tutorial.
import pandas as pd
# Ensure you have installed fastparquet library
df = pd.read_parquet('/Users/harshsinghal/Downloads/part-00263-e638c5dd-3c3d-4738-8d52-dc1e9f44de3a.c000.gz.parquet')
# Write unique hostnames to a file
with open("url_host_names_sample.txt", "w") as f:
f.write('\n'.join(list(set(df['url_host_name']))) + '\n')
3. Insert into a Postgres database with pg_similarity extension installed. For the db I'll use this Docker image.
docker run -d \
--name postgres-pgsim \
-e POSTGRES_PASSWORD=password123* \
-p 5432:5432 \
-e PGDATA=/var/lib/postgresql/data/pgdata \
-v /Users/harshsinghal/workspace/scraper:/var/lib/postgresql/data \
littlebobbytables/postgres-pg_similarityOnce the container is running connect to it and load the domain list and run interesting queries.
docker exec -it postgres-pgsim /bin/bashOnce in become the postgres user by issuing su - postgres
Then issue psql
On the postgres prompt issue the following to create the extension.
CREATE EXTENSION pg_similarity;
I'll show a few examples on the domain dataset in this post but recommend you look at the documentation related to this extension here.
CREATE TABLE cc_domain_sample
(url_domain varchar);
COPY cc_domain_sample FROM '/var/lib/postgresql/data/url_host_names_sample.txt' WITH (FORMAT csv);
Now that we have the data into our table, let us run some queries.
with tb1 as
(
select
url_domain
from
cc_domain_sample limit 10
)
,
tb2 as
(
select
url_domain
from
cc_domain_sample limit 10
)
select
tb1.url_domain,
tb2.url_domain,
lev(tb1.url_domain, tb2.url_domain) as lev_dist,
jaro(tb1.url_domain, tb2.url_domain) as jaro_dist,
euclidean(tb1.url_domain, tb2.url_domain) as euclidean_dist,
soundex(tb1.url_domain, tb2.url_domain) as soundex_dist
from
tb1,
tb2 ;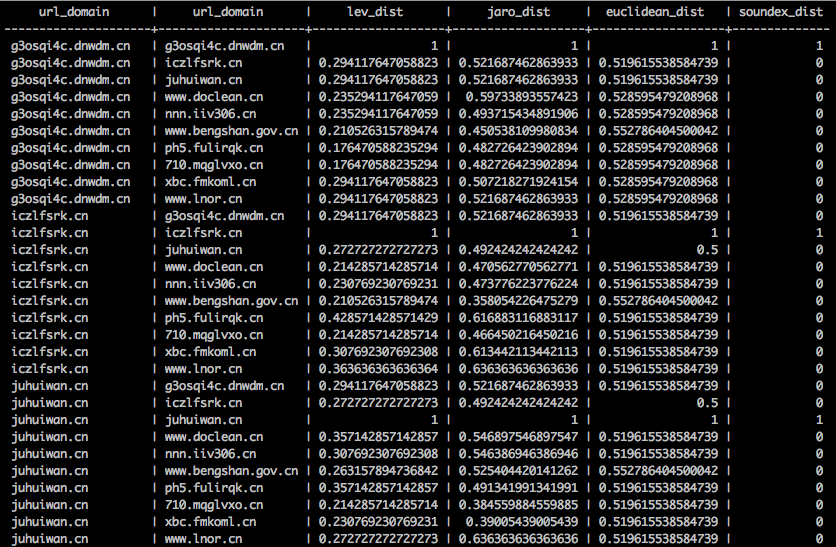
There is much to tweak when using this extension to gain more performance and I'll leave you to explore more.
Take care.

