
BigBanyanTree: Parsing HTML source code with Apache Spark & Selectolax
Dive into the world of data extraction! Learn how to parse HTML source code from Common Crawl WARC files with Apache Spark and Selectolax for insightful analysis and unlock the potential of HTML source code.

Common Crawl WARC files consist of webpage HTML source code and contain a wealth of information waiting to be extracted. In this blog, we'll explore how to extract various fields from HTML source code using Apache Spark and Selectolax.
But before we get our hands dirty with extracting information from HTML source code, let's understand more about WARC files.
WARC Files
WARC, short for Web ARChive, is the industry standard format for web archiving. Developed as a successor to the ARC format, it can store multiple resources, request and response headers, additional metadata, and record types like revisit, metadata and conversion. It also provides scalability and standardization.
Here is an example of the data in a WARC file
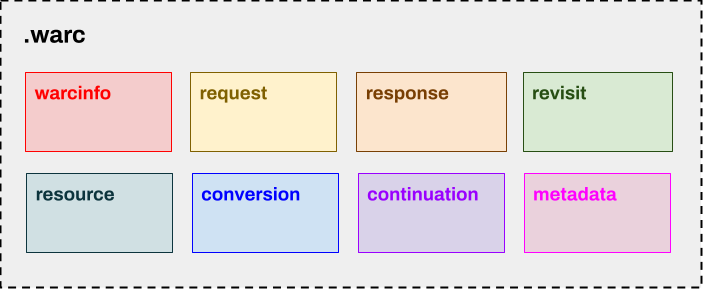
WARC files are divided into eight distinct pieces called records, each with their meaning and metadata attributes. For parsing of HTML source code, we'll be focusing mainly on the server response records. You can read about each record type in greater detail here.
To help us work with these WARC files, we'll make use of the warcio library. Let's get hands-on with some code.
Working with WARC files
To iterate through the records in WARC files, we can use the ArchiveIterator from warcio.
All the code samples in this blog were executed on an Apache Spark cluster in standalone mode. Check out how to set up your own local Apache Spark cluster here.
Let's code up an example of how we can access different fields in a WARC file like so:
from warcio.archiveiterator import ArchiveIterator
input_file = "CC-MAIN-20221126080725-20221126110725-00000.warc"
# WARC files contain a large no. of records, let's visualize 5
max_records = 5
with open(input_file, 'rb') as stream:
print(f"Parsing WARC file {input_file} ...\n")
record_idx = 0
for record in ArchiveIterator(stream):
record_idx += 1
# print the record headers
print(f"Record Headers: {record.rec_headers}")
if record_idx == max_records:
breakOn running the above code, we get
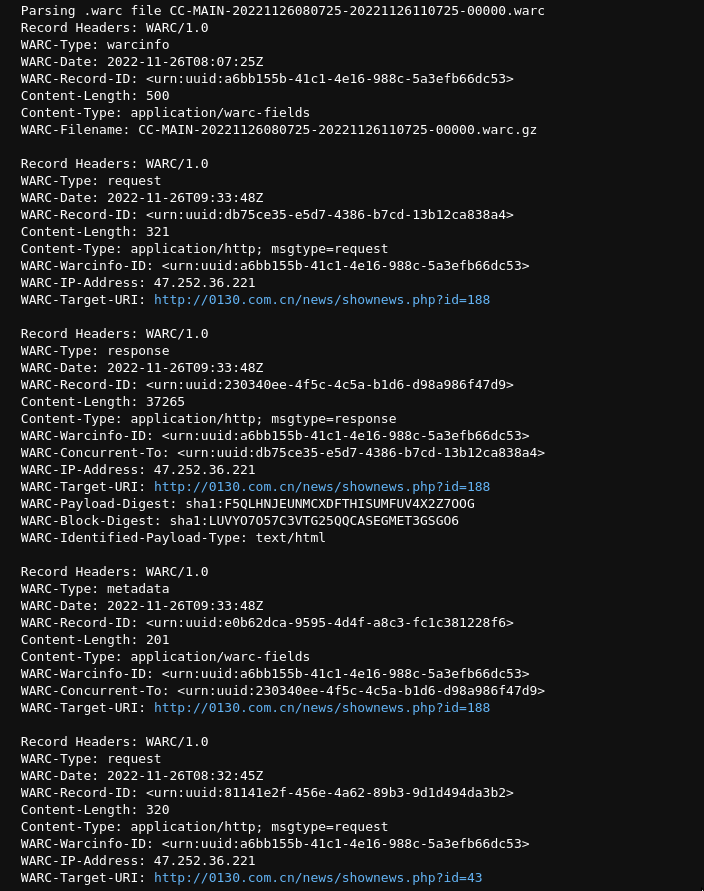
From the output above, we can see the different kinds of records present in this WARC file, namely warcinfo, request, response and metadata records. Each request and response has an IP address and Target URI.
The IP address field contains the server's IP, which contains the retrieved resource. This field helps in documenting the origin of the retrieved resource.
The Target URI contains the original Uniform Resource Identifier, typically a URL of the retrieved resource.
Apart from the record headers themselves, we can also retrieve valuable data from the HTTP Headers. Details such as the server, content type, user-agent etc. We can do this using
print(f"HTTP Headers: {record.http_headers}")The HTTP headers contain information such as
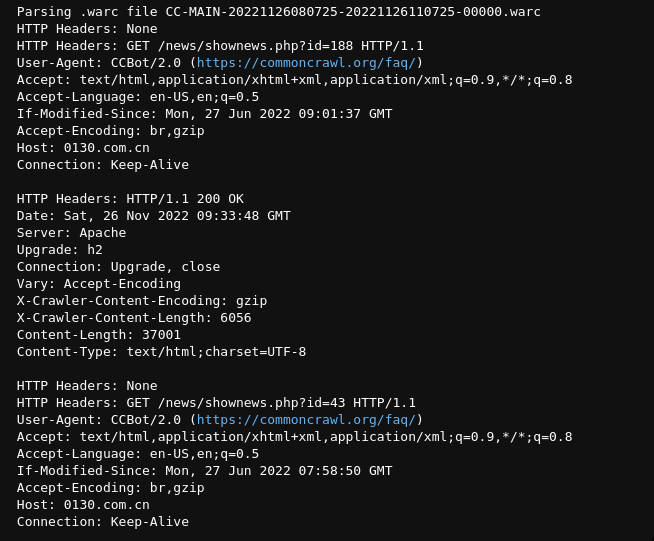
We've just been printing out these headers until now. Let's extract these header fields to be part of a spark data frame.
# using the same input file
with open(input_file, 'rb') as stream:
for record in ArchiveIterator(stream):
# Check if record is a response
if record.rec_type == "response":
# Record Headers
ip_address = record.rec_headers.get_header("WARC-IP-Address")
target_uri = record.rec_headers.get_header("WARC-Target-URI")
content_type = record.rec_headers.get_header("Content-Type")
# HTTP Headers
server = record.http_headers.get_headers("Server")
print(f"IP Address: {ip_address}")
print(f"Target URI: {target_uri}")
print(f"Content Type: {content_type}")
print(f"Server: {server}")We've dealt extensively with WARC files till now. Now let's move on to the show's star, the WARC record data, namely the HTML source code.
We need to use a web scraping library to parse this source code. One popular option is BeautifulSoup (bs4), but we opted to use a faster alternative, selectolax.
Selectolax
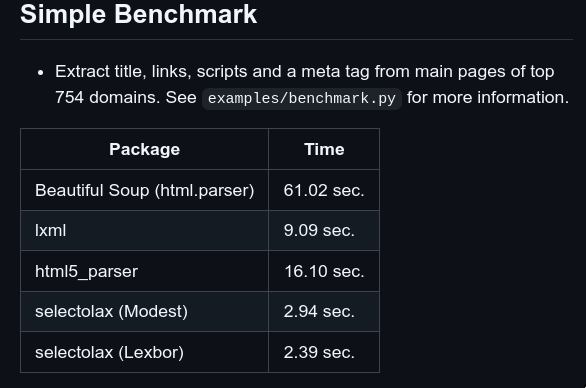
selectolax is a fast HTML5 parser with CSS selectors. Compared to the more popular bs4 (Beautiful Soup) library selectolax provides significant speedups as illustrated in this benchmark
Title Extraction
Let's see how we can put this extra speed to good use
from selectolax.parser import HTMLParser
# get the raw stream of data from the WARC record
raw_txt = record.raw_stream.read()
# convert the raw text into string and perform normalizations
str_txt = str(raw_txt).strip().lower().replace('\t', ' ')
# load the normalized text into selectolax HTML parser
slax_txt = HTMLParser(str_txt)
# extract web page title
title = slax_txt.tags('title')[0].text().strip()HTML parsing with selectolax
On running the above code, you might end up with something like this
\xe6\xbd\xad\xe5\xad\x90,\xe7\x9f\xbd\xe5\x93\x81\xe8\x8f\xaf\xe5\xbb\x88 \xe5\x8f\xb0\xe4\xb8\xad\xe5\xb8\x82|\xe6\xbd\xad\xe5\xad\x90\xe5\x8d\x80 \xe5\x94\xae 598\xe8\x90\xac \xe9\x9b\xbb\xe6\xa2\xaf\xe8\x8f\xaf\xe5\xbb\x88 \xe5\x8f\xb0\xe4\xb8\xad\xe4\xbd\x8f\xe5\x95\x86\xe4\xb8\x8d\xe5\x8b\x95\xe7\x94\xa2 \xe5\x8c\x97\xe5\xb1\xaf\xe5\xba\x97 [104\xe5\xa0\xb1\xe7\xb4\x99\xe6\x88\xbf\xe5\xb1\x8b\xe7\xb6\xb2]This is because the title is still in the form of a byte stream. To convert this into human-readable text (UTF-8), we can use Python's encode and decode functions like so
def encode_byte_stream(input_stream):
return input_stream.encode('utf-8').decode("unicode_escape").encode("latin-1").decode("utf-8", errors="replace")Applying this function on the title byte stream, we get
潭子,矽品華廈 台中市|潭子區 售 598萬 電梯華廈 台中住商不動產 北屯店 [104報紙房屋網]Script Tag Extraction
Secondly, we will aim to determine all the JavaScript libraries used in each webpage. We can accomplish this using the src attribute of HTML script tags. For this, we use the following implementation
src_attrs = [
script.attributes.get('src')
for script in slax_txt.tags('script')
if script.attributes.get('src')
]From this, we can get outputs such as
[
'https://ajax.googleapis.com/ajax/libs/jquery/3.2.1/jquery.min.js',
'/js/jquery/3.3.1/jquery.min.js',
'/js/jqueryplugin/migrate/3.0.0/jquery-migrate-3.0.0.min.js',
'/js/jqueryplugin/makeshop_bxslider/4.1.1/jquery.bxslider.min.js'
]Spark processing
Now to finally put all these sections together into a single function.
from pyspark.sql.types import StructType, StructField, StringType, ArrayType
################# DataFrame Schema ######################
output_schema = StructType([
StructField("year", StringType()),
StructField("ip", StringType(), True),
StructField("host", StringType(), True),
StructField("title", StringType(), True),
StructField("server", StringType(), True),
StructField("script_src_attrs", ArrayType(StringType()), True)
])
################# WARC Processing Functions ######################
def encode_byte_stream(input_stream):
if input_stream is None:
return None
return input_stream.encode('utf-8').decode("unicode_escape").encode("latin-1").decode("utf-8", errors="replace")
def process_record(record: ArcWarcRecord):
"""Return tuple containing ip, url, server and extracted scripts and emails if record is of response type"""
if record.rec_type == "response":
ip = record.rec_headers.get_header("WARC-IP-Address", "-")
url = record.rec_headers.get_header("WARC-Target-URI", "-")
server = record.http_headers.get_header("Server")
raw_text = record.raw_stream.read()
str_text = str(raw_text).strip().lower().replace('\t', " ").replace('\n', "")
slax_txt = HTMLParser(str_text)
# Extract page title
title = slax_txt.tags('title')[0].text().strip()
# Extract script src attributes
src_attrs = [
script.attributes.get('src')
for script in slax_txt.tags('script')
if script.attributes.get('src')
and not script.attributes.get('src').startswith('data:')
]
return (args.year, ip, url, title, server, src_attrs)
return NoneThis function packages all the selectolax parsing tasks to return a tuple containing the fields:
- WARC file crawl year
- WARC IP Address
- WARC Target URI
- Webpage Title
- WARC Response Server
- Extracted Script
srcattributes
We also define an output data frame schema to validate the extracted data's datatypes, and store the processed data in parquet format later.
args used in the code snippets here are arguments taken as CLI inputs from the user, using argparse.def process_warc(filepath):
"""Read WARC file and yield processed records"""
with open(filepath, 'rb') as stream:
for record in ArchiveIterator(stream):
result = process_record(record)
if result:
yield result
def proc_wrapper(_id, iterator):
"""Wrapper function for `process_warc` to handle multiple WARC files"""
for filepath in iterator:
for res in process_warc(filepath):
yield resThe functions process_warc and proc_wrapper make the processing code more readable.
################# Main Execution ######################
# Load the WARC file paths from the input file
data_files = spark.sparkContext.textFile(args.input_file)
# Repartition to manage the workload
data_files = data_files.repartition(10)
# Process WARC files and extract data
output = data_files.mapPartitionsWithIndex(proc_wrapper)
# Convert the processed RDD to a DataFrame
df = spark.createDataFrame(output, output_schema)
# Handle array columns by concatenating the arrays
array_columns = ['script_src_attrs']
for col_name in array_columns:
df = df.withColumn(col_name, concat_ws("|", col(col_name)))
# Repartition for better write performance and save as Parquet
df.repartition(1).write.mode("append").parquet(args.output_dir)Now for applying the previous functions, we first load the WARC file paths from the input file, which is a warc.paths file and repartition the loaded files across the spark cluster. Then we map the proc_wrapper function to each of the partitions present in the cluster. On converting the spark.sql.DataFrame to pandas.DataFrame, we concatenate the lists of extracted script source attributes delimited by |. Finally, we repartition to combine all partitions into one and write to disk.
Phew! I know this has been a lot of information to take in but you finally have all the tools to extract your custom data from CommonCrawl data dumps using selectolax and pyspark.
Open Source 🤗 Datasets
The dataset generated using the above methods is open-sourced and available on HuggingFace 🤗 for download. I encourage you to tinker with the dataset and can't wait to see what you build with it!

The dataset has two parts (separated as directories on HF):
- ipmaxmind_out
- script_extraction_out
"ipmaxmind_out" has IPs from response records of the WARC files enriched with information from MaxMind's database.
"script_extraction_out" has IP, server among other columns, and the src attributes of the HTML content in the WARC response records. Visit the datasets' HuggingFace repositories for more information.


