
Multi-Doc RAG: Leverage LangChain to Query and Compare 10K Reports
Embark on a deep dive into RAG as we explore QnA over multiple documents, and the fusion of cutting-edge LLMs and LangChain. Learn how LangChain works along the way!

RAG is a fascinating approach towards QnA and assistants to enhance LLMs' knowledge beyond fine-tuning. In a world brimming with information and fine-tuning being compute expensive, the ability to synthesize knowledge from multiple documents has been a boon.
Most tutorials out there showcase RAG on a single document/PDF or do not distiguish between multiple documents. We'll see how to do that as well.
Introducing dafinchi.ai
dafinchi.ai is a powerful Retrieval-Augmented Generation (RAG) tool that allows you to chat with financial documents like 10-Ks and earnings transcripts. Whether you need to compare companies, extract insights from disclosures, or analyze performance trends, dafinchi.ai makes it easier than ever.
Explore the world of financial data with advanced AI, and stay ahead in making informed decisions.
Learn MoreUnderstanding RAG
RAG (Retrieval-Augmented Generation) is a process that enables LLMs to use external knowledge bases outside of its training data. Building RAG applications generally consist of these steps:
- Ingest documents/knowledge source
- "chunk" and process the documents
- Get embeddings for the chunk and store them in a vector DB
- Retrieve the embeddings based on the query
- Pass the retrieved text chunks to the LLM as "context"
Get started with LangChain
To build the Multi-Doc RAG application, we'll be using the LangChain library. LangChain is a powerful library designed to do anything and everything with LLMs. It has a huge number of integrations with multiple libraries providing innumerable utilities. LangChain also supports (nearly) all your favourite LLM API providers! It can be used to create Chatbots, for summarization, workflow automation, and much more.
According to the LangChain documentation:
LangChain is a framework for developing applications powered by language models. It enables applications that:
- Are context-aware: connect a language model to sources of context (prompt instructions, few shot examples, content to ground its response in, etc.)
- Reason: rely on a language model to reason (about how to answer based on provided context, what actions to take, etc.)
Check out some cool projects by the community. Start building with LangChain by having a look at the quickstart guide accompanied by a couple of tutorials (like ours 😉).
Building the RAG Application
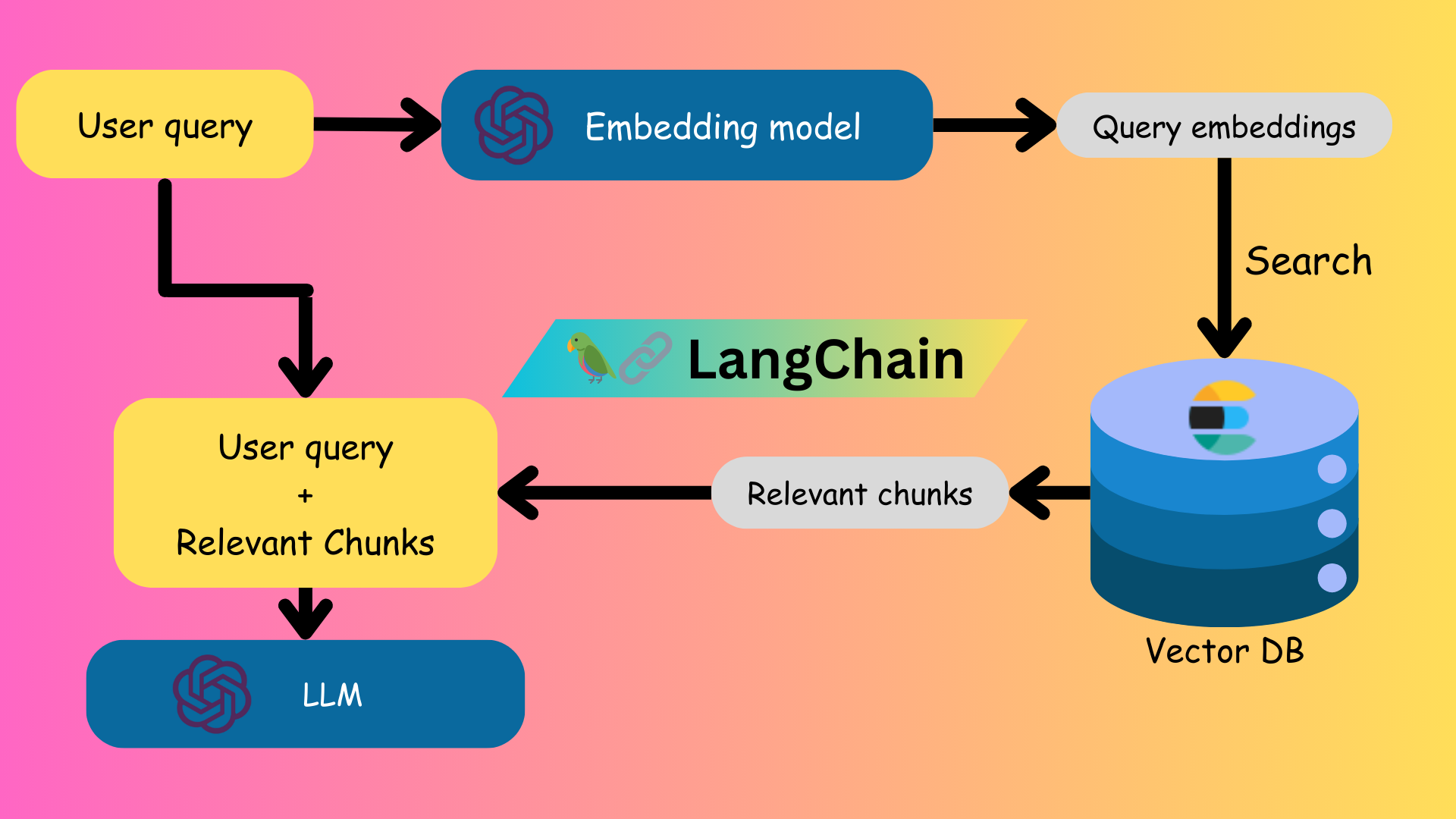
Let us get building!
Pre-Requisites
To get the text and tables from the PDF documents, we'll be using the Unstructured API. Unstructured is an amazing open-source library (github) that has a wide suite of funcionalities catering to a variety of data formats.
In our case, we are interested in parsing tables along with normal text.This is where Unstructured excels at. It is exceptional at parsing tables and also gives tables in HTML format. We'll be using their free API (capped at 1000 pages/month). Create an account and follow their instructions to receive the free API URL and key.
Now, install the necessary packages:
pip install "unstructured[pdf]" lxml pydantic# Import the necessary modules and functions
from unstructured.partition.pdf import partition_pdf
from pydantic import BaseModel
from typing import Any
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.retrievers import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain_community.vectorstores.elasticsearch import ElasticsearchStore
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import (
RunnableLambda,
RunnablePassthrough
)
from langchain_core.documents import Document
from langchain.output_parsers import JsonOutputToolsParser
import uuid
from typing import Union
from operator import itemgetter
import pickle
from itertools import chainmodel = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-1106")Ingesting and Pre-processing
# Define list containing pdf paths and pdf names to be used throughout later on
pdf_paths = ["./AAPL.10K.2023.pdf", "./AMD.10K.2023.pdf", "./IBM.10K.2023.pdf"]
pdfs = ["AAPL.10K.2023.pdf", "AMD.10K.2023.pdf", "IBM.10K.2023.pdf"]Extracting and Chunking
Unstructured also takes care of chunking the PDFs for us. It has a smart chunking strategy that chunks based on sections, and other parameters passable by us.
raw_pdfs_elements = []
# Get parsed elements for each PDF
for i,pdf_path in enumerate(pdf_paths):
raw_pdfs_elements.append(
partition_pdf(
# https://unstructured-io.github.io/unstructured/apis/api_parameters.html
filename=pdf_path,
extract_images_in_pdf=False,
infer_table_structure=True,
chunking_strategy="by_title",
max_characters=1800,
new_after_n_chars=1500,
combine_text_under_n_chars=1000,
image_output_dir_path="./",
url=<your_api_base_url>,
token=<your_api_key>,
)
)
# store the parsed elements as pickles to reuse them whenever necessary
with open(f'{pdf_path}-{i}.pkl', 'wb') as f:
pickle.dump(raw_pdfs_elements[i], f)Here, I have used a conservative 1800 character limit for chunks because I was paranoid about LLMs not utilizing their long context windows. But I recommend increasing the chunk size values by ~300-400 or even more if you have room for experimenting!
Load from pickle
raw_pdf_elements = []
pickle_paths = ["./AAPL.10K.2023.pdf-0.pkl", "./AMD.10K.2023.pdf-1.pkl", "./IBM.10K.2023.pdf-2.pkl"]
for pdf in pickle_paths:
with open(f"{pdf}", 'rb') as f:
raw_pdf_elements.append(pickle.load(f))
Processing Extracted Chunks
We now need to separate the elements by their type—tables and text. For this we define a simple Pydantic BaseModel class to store the text and the corresponding type. Then, the table and text elements are stored in different variables.
class Element(BaseModel):
type: str
text: Any
# Categorize by type
categorized_elements = [
[
Element(type="table", text=str(element.metadata.text_as_html))
if "unstructured.documents.elements.Table" in str(type(element))
else Element(type="text", text=str(element))
for element in raw_pdf_element
]
for raw_pdf_element in raw_pdfs_elements
]
table_elements = [ [e for e in categorized_element if e.type == "table"] for categorized_element in categorized_elements ]
text_elements = [ [e for e in categorized_element if e.type == "text"] for categorized_element in categorized_elements ]Notice that we are getting the HTML table (element.metadata.text_as_html) instead of plain text. This is because GPT 3.5 is particularly good at interpreting HTML tables and does a horrible job of understanding plain text tables. A plain text table looks like so:
Plain text table
Netrevenue:
Data Center
Client
Gaming
Embedded
Total net revenue
Operating income (loss):
Data Center
Client
Gaming
Embedded
All Other
Total operating income (loss)
December2022
31,
Year Ended
(In millions)
December 25,
2021
$
6,043
$
3,694
6,201
6,887
6,805
5,607
4,552
246
$
23,601
$
16,434
$
1,848 $
991
1,190
2,088
953
934
2,252
44
(4,979)
(409)
$
1,264 $
3,648
All we need is just a bunch of chunked texts and we can then index them in the vectorstore, right? So, what are we doing here? We are converting each chunk to a "document" and adding a metadata field that specifies the PDF from which it was taken. This was something I did (in my spaghetti code) to help me debug what PDF I was retrieving the chunk from. But it ended up serving a much greater purpose!
Don't worry if this is not making sense at this point. Everything becomes clearer when we get to the indexing part.
def get_docs(text_ele):
pdf_docs = []
pdf_docs.extend(
[Document(page_content=ele.text, metadata={"pdf_title":t[1]}) for ele in t[0]]
for i,t in enumerate(zip(text_ele,pdfs))
)
# Flattens the list of 3 lists
pdf_docs = list(chain(*pdf_docs))
return pdf_docs
table_docs = get_docs(table_elements)
text_docs = get_docs(text_elements)Indexing and Retrieving from a Vector DB
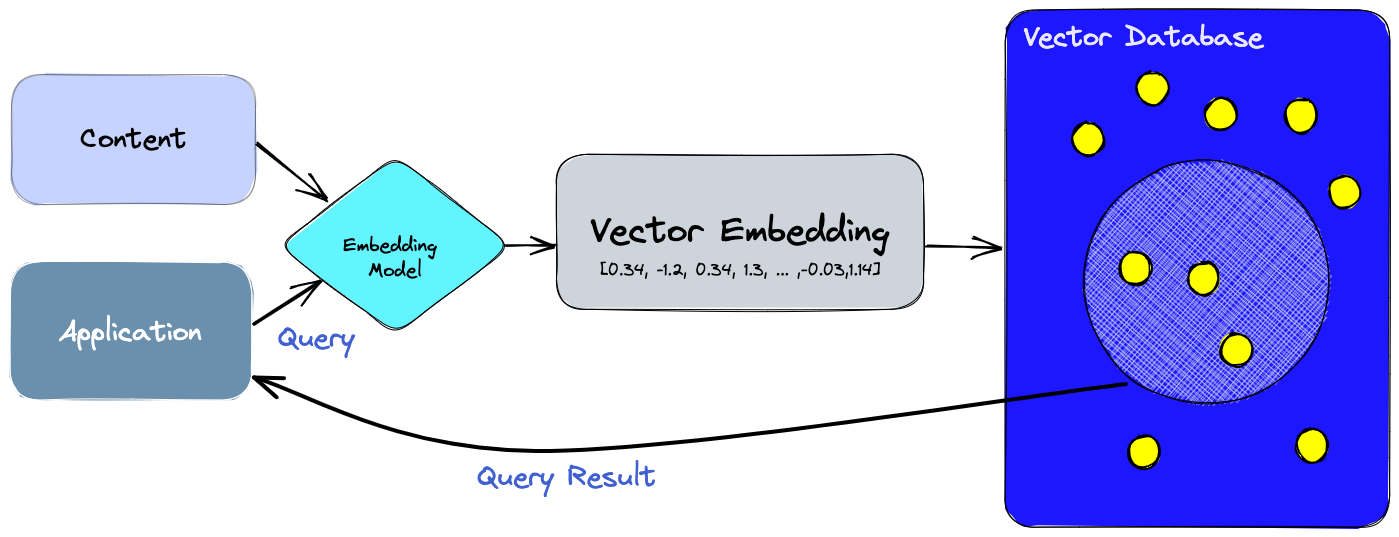
In my experiments, indexing the documents normally in the vectorstore database and then retrieving it performed horribly (for this use case, at least). Using EnsembleRetriever (ensemble of a vector-based retriever and another) gave slightly better results, but they were not satisfactory.
So, to improve our retrieval quality, we'll generate summaries of all the text chunks and index them in the vectorstore. The summary chunks are retrieved based on the user query and the corresponding original text chunks are fed to the model. Let's see all this in action.
Sidenote: LangChain Chains (LCEL)
In simple words, chains are a sequence of calls. It could be calls to LLMs, data processing functions, or any other function, for that matter. The primary and supported way to implement chains in LangChain is with LCEL.
Here's an example chain to concisely demonstrates chaining:
example_chain = ChatOpenAI(model="gpt-3.5-turbo-1106") | StrOutputParser() | ','.join
example_chain.invoke("""Output the following questions separated by a comma:
What is LangChain?
What is LCEL?""")The output would be:
["What is LangChain?", "What is LCEL?"]A breakdown of what's happening:
- When the chain is called using
invoke(), the query is passed to the LLM. - Here,
ChatOpenAIoutputs aAIMessageobject. This is passed toStrOutputParser()as an input which outputs just the string response from the model. - The string output is passed to
','.joinas the input and it outputs the list of questions!
This is quite a interesting concept. Now, let's get on to what we were discussing earlier.
Summarizing Text and Tables
text_summarize_prompt_text = """You are an assistant tasked with summarizing text. \
Give a concise summary of the text. Text chunk: {element} """
text_summarize_prompt = ChatPromptTemplate.from_template(text_summarize_prompt_text)
text_summarize_chain = {"element": RunnablePassthrough()} | text_summarize_prompt | model | StrOutputParser()The above code defines a prompt template with a placeholder (element). RunnablePassthrough() passes the input as is and it gets assigned to "element" resulting in a dict being passed as input to text_summarize_prompt. The input is substituted at the placeholder in the prompt template and the modified prompt is passed to the model. The model output is then parsed with StrOutputParser() to get the text output only from the model response. We then pass the text chunks in batches to get the summaries and store it as a pickle, just in case.
texts = [text.page_content for text in text_docs]
text_summaries = text_summarize_chain.batch(texts, {"max_concurrency": 5})
with open("text_summaries.pkl", 'wb') as f:
pickle.dump(text_summaries, f))We repeat this process for table chunks.
table_summarize_prompt_text = """You are an assistant tasked with summarizing tables. \
Give a concise summary of the table. Table chunk: {table_element} """
table_summarize_prompt = ChatPromptTemplate.from_template(table_summarize_prompt_text)
table_summarize_chain = {"table_element": RunnablePassthrough()} | table_summarize_prompt | model | StrOutputParser()tables = [table.page_content for table in table_docs]
table_summaries = text_summarize_chain.batch(tables, {"max_concurrency": 5})
with open("table_summaries.pkl", 'wb') as f:
pickle.dump(table_summaries, f))"Vectorstores" and "VectorDB" are also used interchangeably.
Indexing the Vectorstore
This is the core component of a RAG application. A vectorstore stores embeddings (a bunch of numbers or vectors) for each text chunk. When the vectorstore is queried, the relevant chunks are retrieved based on some algorithm. To learn more, I encourage you to read this wonderful explainer by Pinecone.
Sidenote: A Note on different Vector DBs
Given that the Vector DB is the core component of any RAG application, it's important to explore different options and see what works best for our application.

Here, we are using ElasticSearch because their LangChain integration offers a straightforward way of filtering retrieval based on document metadata + it's free to use! This is helpful in our case since we are working with multiple PDFs.
Some other noteworthy vectorstores are:
- ChromaDB: ChromaDB is an open-source vector database built for AI applications. It's simple to get started with, is feature rich, and has integrations in popular libraries like OpenAI, LangChain, LlamaIndex and others.
- Qdrant: Qdrant is a highly performant vector database and vector similarity search engine that is open-source. It also provides a producion-ready cloud service!
- Pinecone: Pinecone is managed cloud-native vector database with a simple API and no infrastructure hassles. It's one of the lowest priced vector DB providers with very low latencies.
While these are just a few examples, the landscape of vector store solutions continues to evolve, with new technologies and innovations emerging regularly. We encourage you to explore these options further and evaluate them based on your specific use case requirements and constraints.
Before we create the ElasticSearch vectorDB, we need to setup ElasticSearch first. Install the elasticsearch package:
pip install elasticsearchInstall docker for your platform if you haven't already. Then run the following commands to run the ElasticSearch docker image:
docker network create elasticdocker pull docker.elastic.co/elasticsearch/elasticsearch:8.12.1sudo docker run -p 9200:9200 -e "discovery.type=single-node" -e "xpack.security.enabled=false" -e "xpack.security.http.ssl.enabled=false" docker.elastic.co/elasticsearch/elasticsearch:8.12.1We now create the vectorstore and add documents to it. The vectorstore automatically gets the embeddings for the input docs from the specified OpenAI model and stores them when we add the documents to it.
text_ids = [str(uuid.uuid4()) for _ in text_docs]
table_ids = [str(uuid.uuid4()) for _ in table_docs]
id_key = "doc_id"
# Store summaries as documents and add IDs to them
text_summaries_docs = [
Document(page_content=text_summaries[i], metadata={id_key:text_ids[i], "pdf_title":text_doc.metadata['pdf_title']})
for i,text_doc in enumerate(text_docs)
]
table_summaries_docs = [
Document(page_content=table_summaries[i], metadata={id_key:table_ids[i], "pdf_title":table_doc.metadata['pdf_title']})
for i,table_doc in enumerate(table_docs)
]
vectorstore = ElasticsearchStore(
# https://python.langchain.com/docs/integrations/vectorstores/elasticsearch
embedding=OpenAIEmbeddings(model="text-embedding-3-small"),
es_url="http://localhost:9200",
index_name="summaries_index",
strategy=ElasticsearchStore.ApproxRetrievalStrategy()
)
vectorstore.add_documents(text_summaries_docs);
vectorstore.add_documents(table_summaries_docs);That's it! Our vectorstore is now ready to query from. Let's try out an example.
vectorstore.similarity_search("How much is Apple investing in R&D?", k=2, filter=[{"term": {"metadata.pdf_title.keyword": "AAPL.10K.2023.pdf"}}])Output
[Document(page_content='In 2023, Apple Inc. saw a significant increase in R&D expenses due to higher headcount-related costs, while selling, general, and administrative expenses remained relatively unchanged. The provision for income taxes and effective tax rates for 2023, 2022, and 2021 are also detailed in the report.', metadata={'doc_id': 'a2ce90ec-225f-4081-927e-fdf5e2955096', 'pdf_title': 'AAPL.10K.2023.pdf'}), Document(page_content="Apple Inc. has invested in new business strategies and acquisitions, which come with significant risks and uncertainties. These include distraction of management, unexpected liabilities and expenses, economic and regulatory challenges, inadequate return on capital, potential impairment of assets, and significant write-offs. There is also the risk of failing to obtain required regulatory approvals or facing onerous conditions that could delay or prevent a transaction. These new ventures are inherently risky and may not be successful, potentially impacting the company's business, reputation, results of operations, and financial condition.", metadata={'doc_id': '2f0b20ba-a861-4af2-97a0-64ae81309c68', 'pdf_title': 'AAPL.10K.2023.pdf'})]
To "link" the indexed summaries and their corresponding text chunks, we'll tag them with the same IDs and define a function to get original text chunks.
docs_w_ids = list(zip(text_ids+table_ids,text_docs+table_docs))# Function to get the original text chunks given the retrieved summary texts
def get_orig(summary_docs):
out_docs = [docs[1] for summary_doc in summary_docs for docs in docs_w_ids if docs[0]==summary_doc.metadata[id_key]]
return out_docsLet's see if this works...
get_orig(vectorstore.similarity_search("How much is Apple investing in R&D?", k=2, filter=[{"term": {"metadata.pdf_title.keyword": "AAPL.10K.2023.pdf"}}]))Output
[Document(page_content='Research and Development\n\nThe year-over-year growth in R&D expense in 2023 was driven primarily by increases in headcount-related expenses.\n\nSelling, General and Administrative\n\nSelling, general and administrative expense was relatively flat in 2023 compared to 2022.\n\nApple Inc. | 2023 Form 10-K | 23\n\nProvision for Income Taxes\n\nProvision for income taxes, effective tax rate and statutory federal income tax rate for 2023, 2022 and 2021 were as follows (dollars in millions):', metadata={'pdf_title': 'AAPL.10K.2023.pdf'}), Document(page_content='Apple Inc. | 2023 Form 10-K | 11\n\nInvestment in new business strategies and acquisitions could disrupt the Company’s ongoing business, present risks not originally contemplated and materially adversely affect the Company’s business, reputation, results of operations and financial condition.\n\nThe Company has invested, and in the future may invest, in new business strategies or acquisitions. Such endeavors may involve significant risks and uncertainties, including distraction of management from current operations, greater-than-expected liabilities and expenses, economic, political, legal and regulatory challenges associated with operating in new businesses, regions or countries, inadequate return on capital, potential impairment of tangible and intangible assets, and significant write- offs. Investment and acquisition transactions are exposed to additional risks, including failing to obtain required regulatory approvals on a timely basis or at all, or the imposition of onerous conditions that could delay or prevent the Company from completing a transaction or otherwise limit the Company’s ability to fully realize the anticipated benefits of a transaction. These new ventures are inherently risky and may not be successful. The failure of any significant investment could materially adversely affect the Company’s business, reputation, results of operations and financial condition.', metadata={'pdf_title': 'AAPL.10K.2023.pdf'})]
Retrieving from the Vectorstore
Our retriever must be capable of retrieving chunks from multiple sources/PDFs depending on the query. For example, if the query is "How much are Apple and AMD investing in R&D?", then the LLM must be equipped with context from both the PDFs to give the correct answer. This can be done by separating the queries and also getting the name of the PDF to query from.
get_pdf_query = """You are an assistant tasked with generating additional questions from the given query. \
Given a set of questions, give the relevant questions (in the format as shown) pertaining to each individual company \
in the query IF there are more than one. Also give the report name it corresponds to.
Report names:
AMD.10K.2023.pdf
AAPL.10K.2023.pdf
IBM.10K.2023.pdf
CSCO.10K.2023.pdf
UBER.10K.2023.pdf
<--example start-->
Query: What are the equity compensation plans of AMD and Cisco?
Answer:
What are the equity compensation plans of AMD?, AMD.10K.2023.pdf
What are the equity compensation plans of Cisco?, CSCO.10K.2023.pdf
<--example end-->
<--example start-->
Are there any ongoing legal disputes with Uber?
Answer:
Are there any ongoing legal disputes with Uber?, UBER.10K.2023.pdf
<--example end-->
Query: {user_query}
Answer:
"""
get_pdf_query_prompt = ChatPromptTemplate.from_template(get_pdf_query)
get_pdf_query_chain = {"user_query": RunnablePassthrough()} | get_pdf_query_prompt | model | StrOutputParser()Testing it out...
get_pdf_query_chain.invoke("How much are apple and AMD investing in R&D?")'How much is Apple investing in R&D?, AAPL.10K.2023.pdf\nHow much is AMD investing in R&D?, AMD.10K.2023.pdf'Let's define two functions to parse this response and retrieve context from the individual PDFs.
# Function to get the context from the separated query and the respective PDFs
def get_context(pdf_response):
context_out = []
for resp in pdf_response.split('\n'):
context_out.append(
get_orig(
vectorstore.similarity_search(resp.split(',')[0], k=2, filter=[{"term": {"metadata.pdf_title.keyword": resp.split(',')[1].strip()}}])
)
)
return context_out# Format the the response to differentiate the contexts
def parse_context(contexts):
str_out = ""
for context in contexts:
str_out += "CONTEXT FROM " + context[0].metadata['pdf_title'] + "\n"
if len(context)==1:
continue
for c in context:
str_out += c.page_content + "\n\n"
return str_outPutting all this into a chain that gets the context given a query...
context_chain = context_chain = get_pdf_query_chain | get_context | parse_contextLet's see how it all has come together.
context_chain.invoke("How much is Apple and AMD investing in R&D?")Retrieved and formatted context
CONTEXT FROM AAPL.10K.2023.pdf
Research and Development
The year-over-year growth in R&D expense in 2023 was driven primarily by increases in headcount-related expenses.
Selling, General and Administrative
Selling, general and administrative expense was relatively flat in 2023 compared to 2022.
Apple Inc. | 2023 Form 10-K | 23
Provision for Income Taxes
Provision for income taxes, effective tax rate and statutory federal income tax rate for 2023, 2022 and 2021 were as follows (dollars in millions):
CONTEXT FROM AAPL.10K.2023.pdf
Apple Inc. | 2023 Form 10-K | 11
Investment in new business strategies and acquisitions could disrupt the Company’s ongoing business, present risks not originally contemplated and materially adversely affect the Company’s business, reputation, results of operations and financial condition.
The Company has invested, and in the future may invest, in new business strategies or acquisitions. Such endeavors may involve significant risks and uncertainties, including distraction of management from current operations, greater-than-expected liabilities and expenses, economic, political, legal and regulatory challenges associated with operating in new businesses, regions or countries, inadequate return on capital, potential impairment of tangible and intangible assets, and significant write- offs. Investment and acquisition transactions are exposed to additional risks, including failing to obtain required regulatory approvals on a timely basis or at all, or the imposition of onerous conditions that could delay or prevent the Company from completing a transaction or otherwise limit the Company’s ability to fully realize the anticipated benefits of a transaction. These new ventures are inherently risky and may not be successful. The failure of any significant investment could materially adversely affect the Company’s business, reputation, results of operations and financial condition.
CONTEXT FROM AMD.10K.2023.pdf
During the twelve months ended December 31, 2022, we returned a total of $3.7 billion to shareholders through the repurchase of 36.3 million shares of common stock under our stock repurchase program. As of December 31, 2022, $6.5 billion remained available for future stock repurchases under this program. The repurchase program does not obligate us to acquire any common stock, has no termination date and may be suspended or discontinued at any time.
We continued executing our product technology roadmap by delivering a number of new leadership products and technologies during 2022. For Data Center, we launched our 4th Gen AMD EPYC™ processors with next-generation architecture, technology and features, and designed to deliver optimizations across market segments and applications, while helping businesses free data center resources to create additional workload processing and accelerate output. We also unveiled our 3rd Gen AMD EPYC processors with AMD 3D V-Cache technology for leadership performance in technical computing workloads. We introduced the 7 nm Versal™ ACAP VCK5000 development card designed to offer leadership AI inference performance. We announced the availability of the AMD Instinct™ ecosystem, the new AMD Instinct MI210 accelerator and ROCm™ 5 software. Together the AMD Instinct and ROCm ecosystem offers exascale-class technology to a broad base of high performance computing (HPC) and artificial intelligence (AI) customers, designed to address the demand for compute-accelerated data center workloads and reduce the time to insights and discoveries.
CONTEXT FROM AMD.10K.2023.pdf
Our Strategy
AMD is focused on high-performance and adaptive computing technology, software and product leadership. Our strategy is to create and deliver the world’s leading high-performance and adaptive computing products across a diverse set of markets including the data center, embedded, client and gaming. Our strategy is focused on five strategic pillars: compute technology leadership, expanding data center leadership, enabling pervasive artificial intelligence (AI), providing software platforms and developer enablement, and designing custom silicon and solutions.
We invest in high-performance CPUs for cloud infrastructure, enterprise, edge, supercomputing, and PCs. We invest in high-performance GPUs and software for markets such as gaming, compute, AI, and virtual reality (VR) and augmented reality (AR). With the acquisition of Xilinx, Inc. (XIlinx) in February 2022, our product portfolio now includes FPGAs and Adaptive SoCs used in the data center and embedded markets. Also, with the acquisition of Pensando Systems, Inc. in May 2022, we offer high-performance DPUs and next generation data center solutions.
We leverage our high-performance CPU, GPU, FPGA and DPU product portfolios to deliver solutions that are differentiated at the chip level, such as our semi- custom SoCs, Adaptive SoCs, and APUs, and at the systems level, such as PCs, embedded platforms and servers. To expand our data center presence, we now offer the industry’s strongest portfolio of data center computing solutions based on our CPUs, high-performance GPUs, DPUs, FPGAs, and Adaptive SoCs. We have a broad technology roadmap and products targeting AI training and inference spanning cloud, edge and intelligent endpoints. We achieve this through our family of CPUs, GPUs, FPGAs, and Adaptive SoCs.
Querying the LLM
We are nearly done building our RAG application! All that's left is to build a chain that puts together everything done before and gives us the response.
rag_prompt_text = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question \
in as many words as required.
Feel free to go into the details of what's presented in the context down below.
If you don't know the answer, just say "I don't know."
Question: {question}
Context: {context}
Answer:
"""
rag_prompt = ChatPromptTemplate.from_template(rag_prompt_text)
rag_chain = (
{"question": RunnablePassthrough(), "context": context_chain}
| rag_prompt
| model
| StrOutputParser()
)This is the moment of truth. We finally get to test what we have built so far!!
rag_chain.invoke({"question":"What is apple's approach to sustainability and environmental impact?"})Model response
"Apple's approach to sustainability and environmental impact is addressed through compliance with complex and changing laws and regulations worldwide. This includes adherence to environmental, health, and safety regulations, as well as addressing electronic waste, recycling, product design, and climate change. The company's global operations are subject to a wide range of laws and regulations related to environmental impact, and it is committed to meeting these requirements to minimize its environmental footprint."
rag_chain.invoke({"question":"Who are IBM’s main competitors?"})Model response
"IBM's main competitors vary by industry segment and range from large multinational enterprises to smaller, more narrowly focused entities. In the software segment, IBM's principal competitors include Alphabet (Google), Amazon, BMC, Broadcom, Cisco Systems, Informatica, Microsoft, Oracle, Palo Alto Networks, Salesforce, SAP, Splunk, and VMware. Additionally, IBM competes with smaller, niche competitors in specific geographic regions or product segments."
rag_chain.invoke({"question":"What is AMD’s guidance or outlook for future performance?"})Model response
"AMD’s guidance or outlook for future performance is based on current expectations and beliefs, and involves numerous risks and uncertainties that could cause actual results to differ materially from expectations. The forward-looking statements relate to factors such as demand for AMD’s products, the growth and competitive landscape of the markets, international sales, and the sufficiency of AMD’s cash, cash equivalents, and short-term investment balances to fund operations over the next 12 months and beyond. However, it is important to note that these forward-looking statements should not be relied upon as predictions of future events, as there are no assurances that the events or circumstances reflected in these statements will be achieved or will occur."
Bonus: Interactive Demo!
Made using Asciinema (original asciinema)
Concluding Remarks
I referred to a ton of blog posts, and documentation while building this project. They were really helpful in conceiving this blog post. Here are some of the important ones:
 Suchit G
Suchit G

 langchain-ai
langchain-aiI have uploaded all the code over at my GitHub. Feel free to check it out.
Further Refining
This application can be further improved. Some potential improvements can be:
- Organizing code and building well formatted classes and methods to make it more readable and production ready.
- Improving the document processing and ingesting to enable better utilization of tables during retrieval. This would be a major improvement for a more technical use case where accurate numbers and stats are to be retreived, given that tables contain useful numbers and statistics.
- Exploring better retrieval techniques and other vector databases.
- Building automated ingestion, document processing and indexing pipelines.
Summary
In this blog post, we explored the fascinating approach of Retrieval-Augmented Generation (RAG) for building a multi-document RAG application using LangChain. We delved into the steps involved in building such an application, including ingesting documents, processing and chunking text, summarizing text and tables, indexing and storing in a vector database, and retrieving relevant information based on user queries.
Using LangChain, we demonstrated how to handle queries spanning multiple documents by retrieving context from individual sources and providing concise answers using a language model. The process involved parsing user queries if they encompass context from multiple PDFs, retrieving relevant context from PDF documents, and utilizing the retrieved information to generate responses.
Through code examples and explanations, we covered various aspects of building a RAG application, from preprocessing documents to querying the language model for responses. Overall, this post serves as a comprehensive guide to understanding and implementing RAG applications for question-answering tasks, showcasing the power and versatility of LangChain in handling complex language tasks.
Thank you for reading this post. I hope to see you in the next one :)
