
Mastering Object Detection with YOLO
This blog defines object detection and then describes its applications and traditional methods. It further describes each YOLO iteration in detail. It also provides practical insights and commands for training YOLOv8 on custom datasets in Google Colab.

Object Detection
What is Object detection?
 Source: https://www.chooch.com/wp-content/uploads/2023/01/object-detection-new-york-street.jpg
Source: https://www.chooch.com/wp-content/uploads/2023/01/object-detection-new-york-street.jpg
Object Detection is the concept of detecting instances of real-time objects of a certain class in images and videos or in simple terms, it refers to locating objects in an image and labelling them. Object detection has applications in many areas of computer vision, including traffic management, autonomous vehicles, supervision, and various other fields. Every object class has its special features that they are characterized by for eg. A book is detected by a front cover which has the shape of a rectangle and multiple pages etc.
Uses of Object Detection
Transportation Infrastructure
Transportation providers can use object detection to assure safety across their networks, for example, by identifying obstacles on a train track or checking if there's someone present in a restricted area on a work site.
Food Manufacturers
Food manufacturers can use object detection to ensure the integrity of products before they are packaged and sent away.
Autonomous Vehicles
Over the last decade, significant work has been done to create cars that safely drive themselves. Behind this innovation is computer vision. Cars need to be able to detect certain objects (i.e. pedestrians, traffic lights, traffic cones) so that they may make decisions about what to do and where to go.
Surveillance
Object detection plays a crucial role during surveillance, especially by identifying suspicious activities and crowd management. It also helps in automating alarm systems.
Traditional Approaches vs YOLO
CNNs are fundamental in image processing and computer vision, making use of convolutional layers for object detection and feature extraction. While they efficiently perform tasks like image classification, their multi-stage architecture poses challenges for object detection, especially in applications that require object counters and exact locations.
Comparative Analysis
CNNs
- General Purpose: CNNs are very useful for object detection and instance segmentation but may not match YOLOv8’s speed for object detection.
- Architectural Variability: CNN architectures have strengths and weaknesses so it's difficult to choose a specific architecture efficiently.
- Training and Inference: CNNs may not be as suitable for real-time applications due to higher training data and computational resource requirements.
R-CNNs
- Region Proposal: R-CNNs follow a two-stage detection process, generating region proposals before object classification.
- Localization Accuracy: R-CNNs excel in the accuracy of performing the localization but can be computationally expensive due to the multi-stage approach.
- Object Detection: Evolving into Faster R-CNN and Mask R-CNN, R-CNNs improve speed and accuracy.
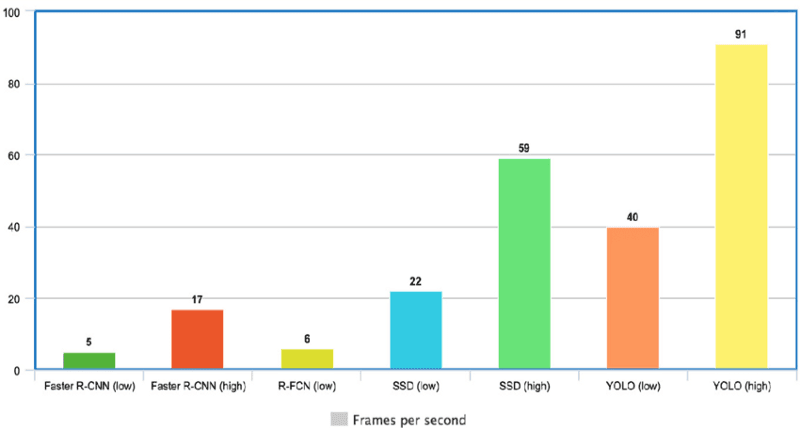 Source: https://images.datacamp.com/image/upload/v1664382693/YOLO_Speed_compared_to_other_state_of_the_art_object_detectors_9c11b62189.png'
Source: https://images.datacamp.com/image/upload/v1664382693/YOLO_Speed_compared_to_other_state_of_the_art_object_detectors_9c11b62189.png'YOLOv8
- General Architecture: YOLOv8 utilizes a neural network architecture that predicts the detection of objects and identifies the object class and also draws bounding boxes around the detections and can also display the confidence score of the detections simultaneously making it very handy for real-life applications.
- Speed: It can process images and videos in real-time, allowing YOLOv8 to identify objects at different resolutions. Performing multiple predictions concurrently allows this hence making it very fast.
- Accuracy: YOLOv8 implements advanced techniques, such as anchor boxes and non-maximum suppression, which enhance the model's performance and reduce false detections. These techniques improve the accuracy of the detections.
 Source: https://miro.medium.com/v2/resize:fit:1358/1*V94aE2HOQO6-YyX3jWAgOw.png
Source: https://miro.medium.com/v2/resize:fit:1358/1*V94aE2HOQO6-YyX3jWAgOw.png
Introduction to YOLO
 Source: https://assets-global.website-files.com/646dd1f1a3703e451ba81ecc/6492ca346ae8260c3efbc433_Yolo-hero-p-800.webp
Source: https://assets-global.website-files.com/646dd1f1a3703e451ba81ecc/6492ca346ae8260c3efbc433_Yolo-hero-p-800.webpYou Only Look Once (YOLO) is a real-time object detection algorithm introduced in 2015 by Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi in their famous research paper, You Only Look Once: Unified, Real-Time Object Detection
In computer vision, one name stands out for its groundbreaking advancements in object detection: Ultralytics. By implementing various new technologies and useful architectures, Ultralytics has significantly improved the standards of object detection with its introduction of the You Only Look Once (YOLO) algorithm.
Decoding YOLO: Neural Network Architecture, Grid Cells, and Loss Functions
The YOLO (You Only Look Once) algorithm revolutionized object detection by introducing a unified approach that predicts bounding boxes and class probabilities directly from full images in a single pass through a neural network.
 Source: https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/63c697fd4ef3d83d2e35a8c2_YOLO%20architecture-min.jpg
Source: https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/63c697fd4ef3d83d2e35a8c2_YOLO%20architecture-min.jpg
- Neural Network Architecture:
YOLO employs a single convolutional neural network (CNN) architecture that simultaneously predicts multiple bounding boxes and their corresponding class probabilities in a single end-to-end network. - Grid Cells:
YOLO divides the input image into a grid of cells. Each cell predicts bounding boxes and class probabilities for objects in its spatial location. The grid allows YOLO to detect objects at different positions in the image efficiently. The grid also helps detect multiple objects belonging to different classes in the same image. YOLO predicts a fixed number of bounding boxes and associated class probabilities for every grid.
In a grid cell, YOLO predicts bounding boxes by regressing from predefined anchor boxes. Each bounding box prediction consists of four coordinates: (x, y) coordinates of the box's center relative to the grid cell, the box's width, and height. Additionally, YOLO predicts the confidence score for each detection displayed above the bounding box, expressing the likeliness of the detection. Class probabilities are also calculated for each bounding box, indicating the accuracy of the object belonging to a specific class. - Loss Function:
Localization loss, confidence loss, and classification loss are combined into a composite loss function used by YOLO. The localization loss calculates the bounding box prediction accuracy by comparing the predicted box coordinates with the ground truth annotations. Inaccurate confidence scores for both background and object predictions are penalized by the confidence loss. Lastly, the difference between ground truth class labels and predicted class probabilities is measured by the classification loss. YOLO learns to accurately assign class labels and localize objects by optimizing this combined loss function during training.
Evolution of YOLO: From YOLOv1 to the Latest Iterations
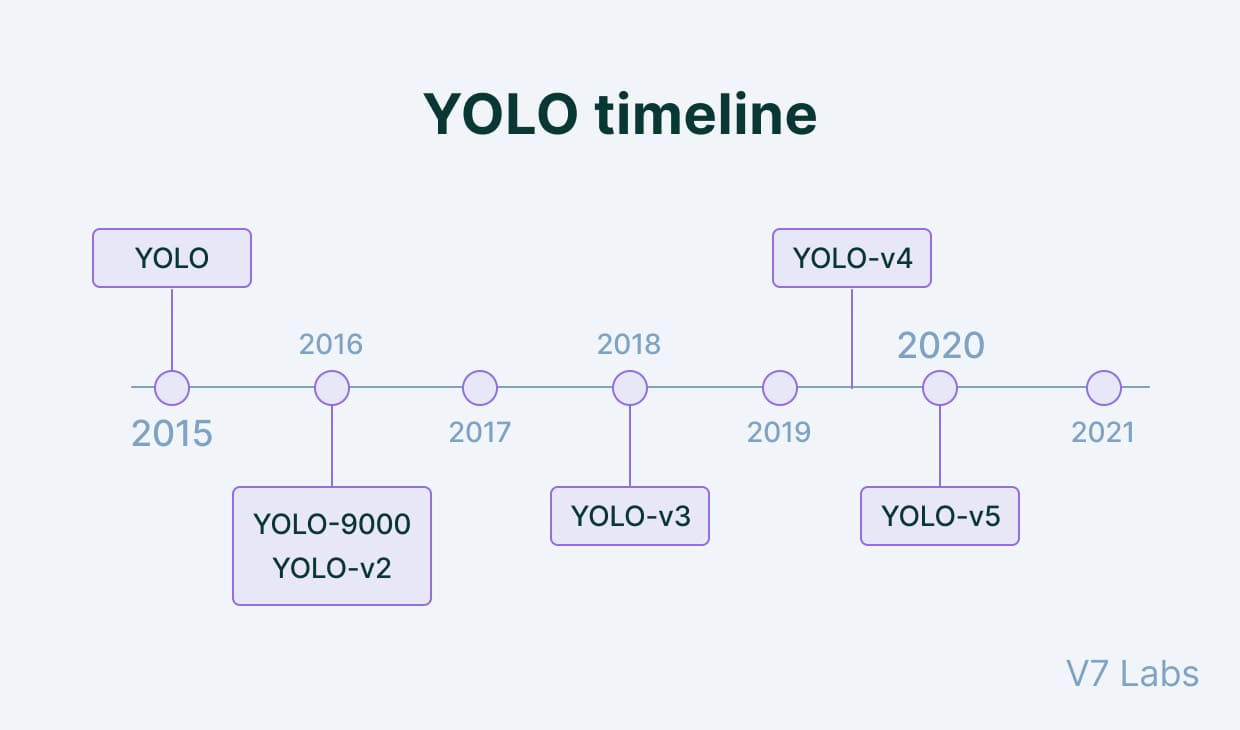 Source: https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/63c697965a86db36ab528b16_YOLO%20timeline-min.jpg
Source: https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/63c697965a86db36ab528b16_YOLO%20timeline-min.jpg
YOLO
YOLOv1 introduced the concept of real-time object detection by framing it as a single regression problem. It used the concept of grid to detect multiple objects in a frame and label them based on their classes. A major drawback was that it couldn't detect small objects.
YOLOv2
 Source: https://www.researchgate.net/publication/349067788/figure/fig5/AS:988450635390987@1612676404944/Architecture-of-the-proposed-YOLOv2-network-framework-The-input-image-has-a-size-of.png
Source: https://www.researchgate.net/publication/349067788/figure/fig5/AS:988450635390987@1612676404944/Architecture-of-the-proposed-YOLOv2-network-framework-The-input-image-has-a-size-of.pngYOLOv2, also known as YOLO9000, was introduced in 2016 to eliminate some of the flaws of the original YOLO algorithm. It was faster and also had a higher accuracy than YOLO and a wider range of object classes. YOLOv2 addressed many shortcomings of its predecessor by introducing several improvements. It implemented batch normalization to stabilize and speed up the training process. Anchor boxes improved the model's ability to detect objects of differing sizes and aspect ratios. YOLOv2 also enhanced feature extraction by introducing a new architecture named Darknet-19.
YOLOv3
YOLOv3 further improved the YOLO architecture and enhanced the quality of object detection by offering better accuracy and speed compared to its predecessors. It raised the resolution of the input photos during training. It harnessed multi-scale detection so that the accuracy of detections improves and the detections are performed more precisely. YOLOv3 included feature pyramid networks (FPN) to extract features at different levels and also improve performance specifically for small objects.
YOLOv4
 Source: https://user-images.githubusercontent.com/26833433/246185689-530b7fe8-737b-4bb0-b5dd-de10ef5aface.png
Source: https://user-images.githubusercontent.com/26833433/246185689-530b7fe8-737b-4bb0-b5dd-de10ef5aface.pngPerformance and efficiency saw a major improvement with YOLOv4. Feature extraction was enhanced using many new innovative technologies, especially the CSPDarknet53 backbone. YOLOv4 attained better accuracy and faster inference using multiple optimization methodologies, including PANet, updated data augmentation approaches, and the Mish activation function. On benchmark datasets, YOLOv4 demonstrated boosted performance, indicating a major improvement in performance and speed in comparison to its predecessors.
YOLOv5
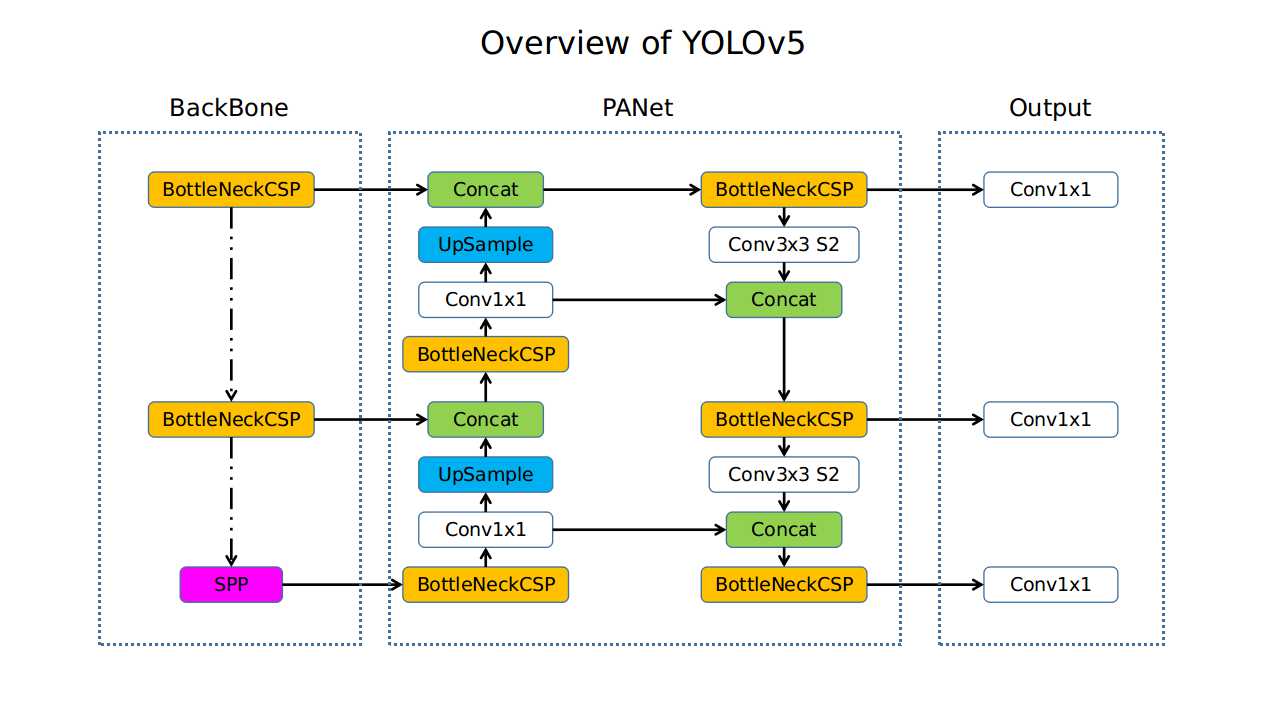 Source: https://user-images.githubusercontent.com/26456083/86477109-5a7ca780-bd7a-11ea-9cb7-48d9fd6848e7.jpg
Source: https://user-images.githubusercontent.com/26456083/86477109-5a7ca780-bd7a-11ea-9cb7-48d9fd6848e7.jpg
YOLOv5 became well-known due to its simple design and intuitive use although it wasn't an official release by the original developers. YOLOv5, created by the open-source community, aimed to preserve excellent performance while streamlining the model design. Researchers and developers may now train custom models with less effort thanks to its streamlined training process and lightweight backbone based on the EfficientNet architecture. Even though there was considerable debate about how it was developed, YOLOv5 produced remarkable outcomes and showed good scope in a large field of real-time applications.
YOLOv6
 Source: https://user-images.githubusercontent.com/26833433/240750557-3e9ec4f0-0598-49a8-83ea-f33c91eb6d68.png
Source: https://user-images.githubusercontent.com/26833433/240750557-3e9ec4f0-0598-49a8-83ea-f33c91eb6d68.pngYOLOv6 is an update to the YOLO trunk and neck that redesigns them with hardware in mind. They call them the EfficientRep Backbone and Rep-PAN Neck. The classification and box-regression heads in all the YOLO iterations up to YOLOv5 have the same characteristics. It has been demonstrated empirically that separating the heads in YOLOv6 by adding more layers improves performance significantly. At a similar output rate, the YOLOv6 model mimics the COCO data set more precisely than the YOLOv5 model. A GPU from Tesla V100 was used to test this.
YOLOv7
 Source: https://blog.roboflow.com/content/images/2022/07/image-33.webp
Source: https://blog.roboflow.com/content/images/2022/07/image-33.webpYOLOv7 became a very widespread and highly stable iteration of YOLO. One important improvement is the use of anchor boxes. These anchor boxes are used to identify items of different shapes. They are available in different aspect ratios. YOLO v7 can detect a greater variety of item forms and sizes thanks to the use of nine anchor boxes, which reduces the number of false positives. To improve performance, a new loss mechanism called "focal loss" is incorporated in YOLO v7. Focal loss modifies the weight of the loss on accurately categorized samples while giving harder-to-detect examples greater weight which is an upgrade in contrast to the conventional cross-entropy loss function employed in earlier iterations of YOLO. A major improvement of YOLOv7 was its speed since it was much faster than any of the previous versions.
YOLOv8
This model builds on the successes of prior YOLO versions and incorporates new advancements to enhance its performance and versatility. The versatility of YOLOv8 is one of its main advantages. It's very efficient when users want to evaluate the performance of the current YOLO iteration with previous iterations, hence making it very useful when multiple iterations of YOLO have to be utilized. YOLOv8 is an excellent choice for a variety of object identification and image segmentation applications due to its adaptability and several other advances. These consist of a loss function, an anchor-free detection head, and a new backbone network. YOLOv8 runs extremely well on a wide range of hardware, including CPUs and GPUs making it very reliable.
Training YOLOv8 On A Custom Dataset
 Source: https://assets-global.website-files.com/63c6be5d69abf87798adedb7/63ee8c2532f513163ffeef7a_cover-yolov8.jpg
Source: https://assets-global.website-files.com/63c6be5d69abf87798adedb7/63ee8c2532f513163ffeef7a_cover-yolov8.jpgTraining YOLO on a custom dataset involves several phases to prepare the data, configure the model, train the network, and evaluate its performance. Here are the various phases typically included in training YOLO on a custom dataset:
- Data Collection and Annotation
Data Preprocessing
Dataset Splitting
Model Configuration
- Detect: To detect the objects in an image or video.
- Segment: For dividing an image or video into regions or pixels that correspond to different objects or classes also known as image segmentation.
- Classify: To identify the class label the object belongs to.
- Train: For training a YOLOv8 model on a custom dataset.
- Val: For validating a YOLOv8 model after the training to check accuracy.
- Predict: To check the efficiency of the model by testing it on a new dataset.
- Export: To export the model for deployment in various formats.
- Track: For tracking objects in real-time using a YOLOv8 model.
-
Args:Key training settings include batch size, learning rate, momentum, and weight decay. The various arguments that can be modified or used are described in Model Configuration
Training:
model=yolov8s.pt: Specifies the model architecture or weights file to be used for training. In this case, it refers to a YOLOv8 variant model with the filename "yolov8s.pt" which is stored automatically in the folder after the training process.data=data.yaml: This is the YAML configuration file containing information about the dataset, such as the paths to image files, annotations, class labels, etc.epochs=25: Specifies the number of training epochs, i.e., the number of times the entire dataset will be fed to the model during training.plots=True: Indicates whether plots or visualizations of training metrics (e.g., loss curves) should be generated during training. The plots can be visualized using the results.png file found in the runs/detect/train directory. An example of the snippet is:Image(filename='runs/detect/train4/results.png', width=600)Model Evaluation
 Source: https://static.wixstatic.com/media/feee33_45603bbe494d41989b0280cbe1503d79~mv2.png/v1/fill/w_640,h_340,al_c,q_85,usm_0.66_1.00_0.01,enc_auto/feee33_45603bbe494d41989b0280cbe1503d79~mv2.png
Source: https://static.wixstatic.com/media/feee33_45603bbe494d41989b0280cbe1503d79~mv2.png/v1/fill/w_640,h_340,al_c,q_85,usm_0.66_1.00_0.01,enc_auto/feee33_45603bbe494d41989b0280cbe1503d79~mv2.pngTo train YOLO on a custom dataset, data collection and annotation are an essential step since they provide the framework for developing a reliable and effective object detection model. During this stage, relevant photos are gathered and bounding boxes are added to indicate the location and class labels of objects of interest. A dataset of at least 2000 images specific to each object class is created.
Firstly, data collection involves collecting a wide range of images that match the object to be detected in real-time scenarios. Depending on the application, these images may come from various sources such as public datasets available on Kaggle or GitHub, etc, web scraping using Google Images, etc, or self-data collection efforts. The dataset must include a variety of object poses, lighting conditions, backgrounds, angles, and scales to facilitate effective model generalization.
After the images are gathered and a dataset has been collected, they must be categorized with the appropriate class names and annotated with bounding boxes that encompass the objects of interest. Annotation can be performed manually or more efficiently using annotation tools automatically. Every bounding box should precisely enclose the thing it depicts so that it can be detected unambiguously. Every object should also have the proper class label associated with it, which corresponds to the kind of object it represents. Paying attention to details is extremely crucial during annotation so as to ensure the efficiency and effectiveness of the annotation performance. Annotated images serve as the ground truth data for training the YOLO model, guiding it to classify objects accurately in unseen images.
Roboflow For Data Annotation
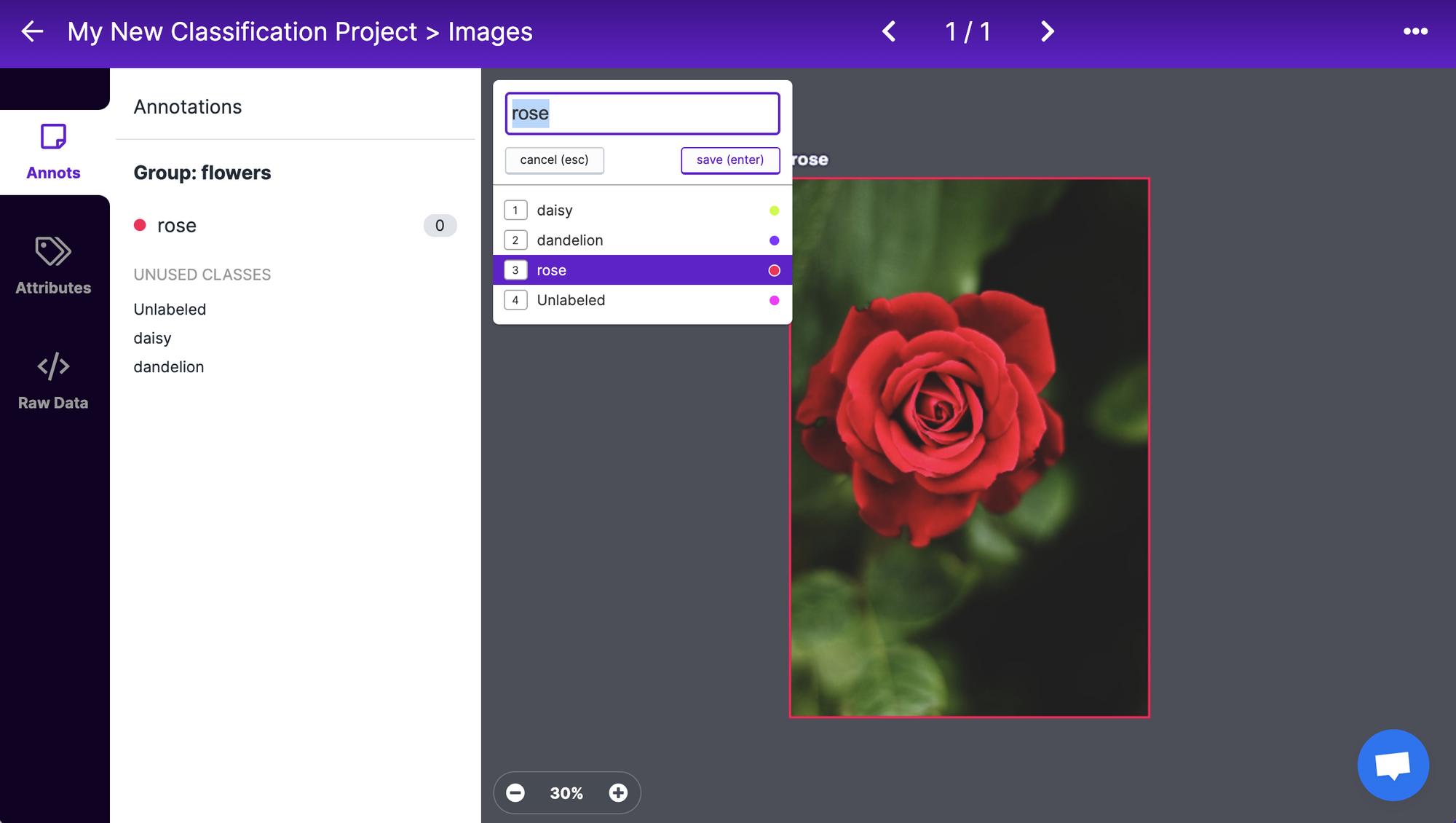 Source: https://blog.roboflow.com/content/images/2021/06/image-17.png
Source: https://blog.roboflow.com/content/images/2021/06/image-17.png Roboflow provides a user-friendly interface that allows annotators to upload images and annotate objects with bounding boxes quickly and accurately. Roboflow offers a customizable annotation interface that allows users to adjust settings such as grid size, auto annotation facilities, and label colors to suit their preferences and specific requirements. It also supports batch annotation, enabling users to annotate multiple images simultaneously. This feature speeds up the annotation process, especially when a huge dataset has to be annotated.
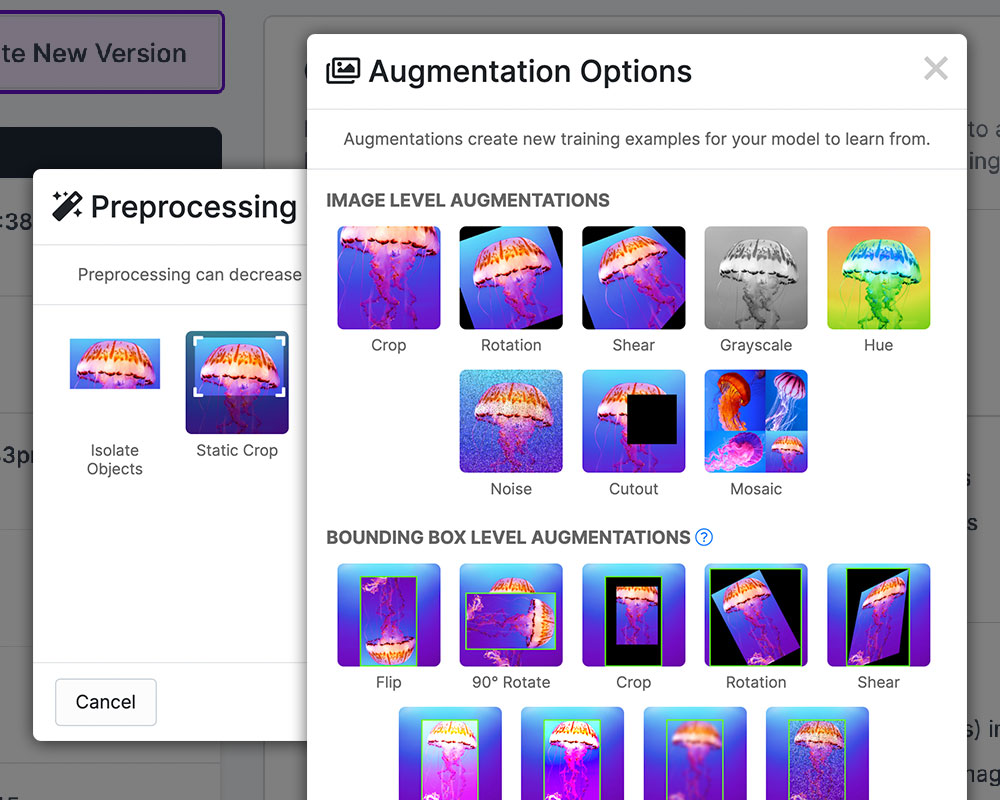 Source: https://assets-global.website-files.com/5f6bc60e665f54545a1e52a5/62d06f7a11808aaacd3742a1_rf_preprocessing_augmentation.jpg
Source: https://assets-global.website-files.com/5f6bc60e665f54545a1e52a5/62d06f7a11808aaacd3742a1_rf_preprocessing_augmentation.jpgData preprocessing and also augmentation of the dataset are essential in readying data for YOLO model training, enhancing compatibility, and optimizing the performance of the model. It includes processes such as image resizing, changing the orientation of the image, and displaying the images in grayscale. These steps are vital for creating a standard for the input data and facilitating effective model convergence during training and preventing issues such as overfitting and underfitting. Annotation using software like Roboflow can further streamline and enhance the annotation process.
A range of preprocessing tools from Roboflow make work easier when preparing data. For example, users can resize photographs to desired dimensions using its image resizing tool, guaranteeing uniformity throughout the dataset. Additionally, Roboflow offers choices for pixel value normalization via modifiable preprocessing pipelines, letting customers change settings to suit their requirements.
Moreover, users can employ data augmentation methods like rotation, flipping, and cropping to increase dataset diversity and improve the accuracy of the model using Roboflow's augmentation facilities. Before completing preprocessing, users can examine augmented photos and change the augmentation parameters as per their preferences.
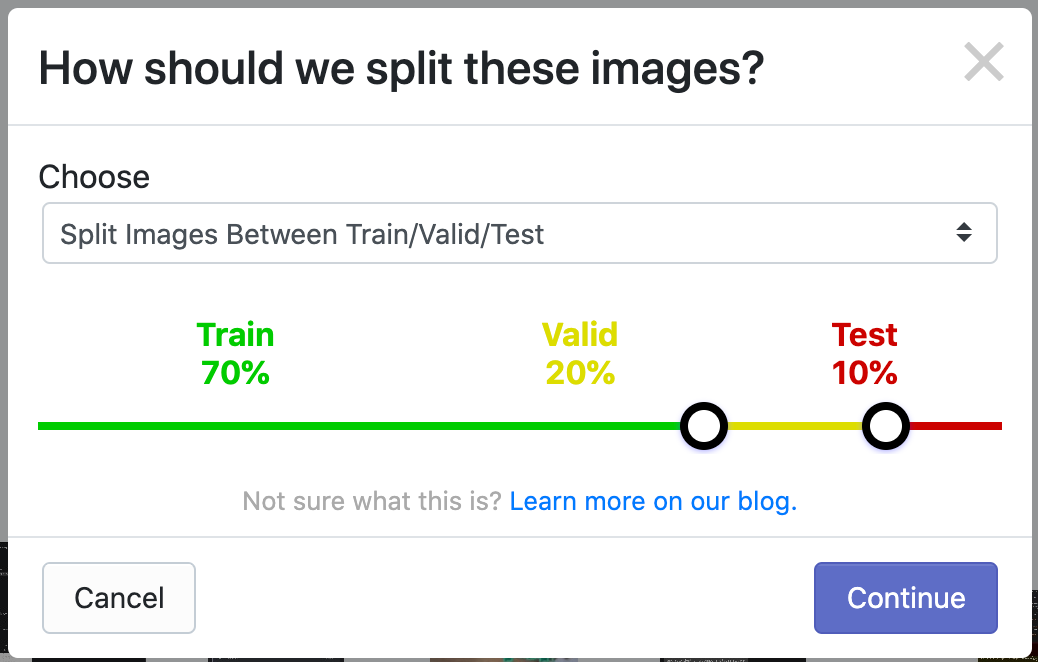 Source: https://blog.roboflow.com/content/images/2020/11/train-test-split-default.png
Source: https://blog.roboflow.com/content/images/2020/11/train-test-split-default.png
Dataset splitting is an essential phase before the training and model configuration. It improves the training and evaluation phases of the model and also enhances performance. Training, validation, and testing are the three separate groups extracted from the annotated dataset. The YOLO model is trained using the training set, containing most of the annotated data, to uncover the underlying patterns and properties. The training set is typically 70–80% of the annotated data.
The validation set is essential for performance analysis, hyperparameter adjustment, and avoiding overfitting. It lets users assess how well the model responds to new data and adjusts model parameters accordingly. The validation set typically contains 10–15% of the annotated data.
Thirdly, the testing set is reserved exclusively for final model evaluation and performance assessment. It provides a measure of the model's effectiveness on unseen data, providing an accurate assessment of its real-world performance. The testing set is kept separate from the training and validation sets and is not used during model training or hyperparameter tuning. Typically, around 10-15% of the annotated data is allocated to the testing set.
Model configuration is a critical phase in training YOLO models, as it involves selecting the appropriate architecture and variant to meet the specific requirements of the object detection task. YOLO offers several versions, each with its architecture and performance characteristics explained in detail above.
In addition to choosing the architecture, model configuration entails defining the number of classes to detect and configuring input size and other hyperparameters. The number of classes corresponds to the types of objects the model will be trained to detect. This parameter directly influences the output layer of the model, affecting the number of neurons and class probabilities predicted by the network. Furthermore, configuring the input size determines the resolution of the input images processed by the model during training and inference. Larger input sizes can lead to more detailed feature representations but may require increased computational resources.
Hyperparameters important for configuring the model are learning rate, batch size, and regularization techniques. During training, these parameters impact the model's convergence and optimization process. To achieve optimal model performance, it is crucial to fine-tune these hyperparameters through experimentation and performance evaluation using validation data.
Using YOLO in Google Colab
The first step includes checking if the notebook is connected to Google Colab using the command !nvidia-smi. It also returns information regarding the status of the GPU.
The next step involves installing the ultralytics library which can be done using !pip installing ultralytics and then we have to import the library using import ultralytics.
Next, we can import the Roboflow API and run the command which is obtained from Roboflow when you click on the export as YOLO format. It is also necessary to run the command CUDA_LAUNCH_BLOCKING=1. Setting the environment variable CUDA_LAUNCH_BLOCKING to 1 forces CUDA kernel launches to be synchronous. This means that when GPU operations are executed, the CPU will wait for them to complete before continuing execution. This can be useful for debugging purposes, as it ensures that any errors or issues related to GPU operations are immediately visible and can be traced back more easily.
The YOLO definition uses the following syntax:
yolo TASK MODE ARGSwhere some of the frequently used tasks are:
Mode:
Model training is a fundamental process in developing YOLO models for object detection tasks, where the model learns to detect the objects it's trained to detect. Training involves feeding annotated data into the model, optimizing its parameters based on the results, and improving its ability to accurately predict object bounding boxes and label the class it belongs to.
During model training, the YOLO architecture processes batches of annotated images, typically using stochastic gradient descent (SGD) or its variants as the optimization algorithm, and the data gets fed to the model as many times as defined in the number of epochs. The model iteratively adjusts its parameters, such as weights and biases, to minimize a predefined loss function that quantifies the disparity between predicted and ground truth bounding boxes and class probabilities. The loss function typically comprises components for localization loss (measuring the accuracy of predicted bounding box coordinates), confidence loss (evaluating the model's certainty in predicting object presence), and classification loss (assessing the accuracy of predicted class probabilities).
An example of a model training process with YOLOv8 can be described as:
!yolo task=detect mode=train model=yolov8s.pt data= data.yaml epochs=25 imgsz=640 plots=True where
Model evaluation is a critical phase in the development and deployment of YOLO object detection models, as it assesses the model's performance in detecting and localizing objects within images or videos. Evaluation metrics provide insights into the model's accuracy, precision, recall, and effectiveness in real-world scenarios. During model evaluation, various metrics and techniques are employed to measure the model's performance and identify areas for improvement. Additionally, we can evaluate the model based on how well it performs on the validation set.
One commonly used metric for evaluating object detection models is mean Average Precision (mAP), which quantifies the model's ability to detect and localize objects across different classes and confidence scores. mAP calculates the average precision for each class and computes the mean across all classes, providing a comprehensive measure of detection accuracy.
Moreover, model evaluation involves assessing the model's performance on a separate testing dataset not used during model training or validation. This ensures an unbiased evaluation of the model's generalization capabilities and ability to detect objects in unseen data. This can be performed by using the val keyword in the mode. It generally uses the below format:!yolo task=detect mode=val model=/content/drive/MyDrive/Face_Mask/Face_masks/runs/detect/train4/weights/best.pt data=data.yaml
Then we ensure the model is completely ready for deployment by confirming the predictions using a separate dataset. The predictions can be made by using the predict mode. This mode uses a special parameter called conf. The parameter conf in the given YOLO command plays the role of setting the confidence threshold for object detection during prediction. This threshold determines the minimum confidence score required for a detected object to be considered valid and included in the final output. An example can be as follows:!yolo task=detect mode=predict model=/content/drive/MyDrive/Face_Mask/Face_masks/runs/detect/train4/weights/best.pt conf=0.25 source=/content/drive/MyDrive/Face_Mask/Face_masks/test/images
Challenges and Limitations of YOLO
- Fine-tuning and Hyperparameter Optimization: Selecting the various hyperparameters like batch size etc can be difficult especially when you have to modify multiple hyperparameters to achieve an efficient model.
- Detection of Small Objects: YOLOv8 may still struggle with accurately detecting small objects within images or videos. This limitation can affect the model's performance in applications where precise localization of small objects is crucial
- Generalization to Unseen Data: While YOLOv8 may perform well on the training and validation datasets, its ability to generalize to unseen data or real-world scenarios remains a challenge. Model overfitting, biases in the dataset, and environmental variations can impact the model's performance in practical applications.
Conclusion
In conclusion, object recognition is an important technology widely used in various industries, including transportation, manufacturing, autonomous vehicles, and surveillance From YOLOv1 to the last iteration YOLOv8. The evolution of the YOLO model has significantly advanced object detection, offering faster estimation speed, improved accuracy, and increased versatility. It also introduced new architectures, optimization techniques, and architectural improvements to overcome challenges posed by real-world object detection tasks, YOLO model training for custom datasets includes a planning process including data collection, annotation, preprocessing, model configuration, training, evaluation, and deployment. Advanced tools and techniques like Roboflow for annotation and data preprocessing simplify the training pipeline and accelerate model development. Overall, YOLO is at the forefront of object recognition research and innovation in computer vision, enabling robust and efficient solutions for real-world applications.
Acknowledgements