
Exploring Leading Large Language Models: A Perspective on Today's AI Giants
Discover the magic of large language models—the heart of AI giants. Take a look at how they have evolved. Join the journey into the future of artificial intelligence!

In the constantly evolving world of artificial intelligence, large language models have become pretty important. Therefore, exploring these models gives us a closer look at the big players today. Today, we would be discovering how they're changing the game in understanding and using language.
Let us dive into this wonderful world of LLMs!
A brief on LLMs and their importance
Large language models(LLM) represent advancements in natural language processing (NLP) by leveraging extensive pre-training on diverse multimodal datasets covering textual, audio, and image inputs. These models acquire a nuanced understanding of patterns, semantics and contextual relationships through unsupervised learning. By encapsulating a broad spectrum of human knowledge, they become adept at comprehending and generating human-like language across various domains.
Furthermore, the versatility of these models extends beyond their pre-trained capabilities. Through fine-tuning procedures, these models can be tailored to specific tasks in sectors like retail, finance, and entertainment, addressing challenges unique to each industry. Applications include text classification, where the models exhibit superior proficiency in categorizing diverse textual inputs, as well as question-answering, document summarization, and text generation, where they demonstrate a great grasp of context and generate contextually relevant responses.
Classification of LLMs

Based on how these models are licensed, we can differentiate on the basis if they are commercial or open-source in nature.
Commercial : These are proprietary solutions developed, maintained, and often licensed by companies. These models find application across diverse sectors, allowing companies to elevate the sophistication of their products and services by leveraging advanced natural language understanding and generation capabilities.
In this blog, we will focus on the following commercial models:
- GPT (Generative Pre-trained Transformer) Models by OpenAI: ChatGPT-3.5 and GPT-4.
- Claude by Anthropic.
- Bard by Google.
Open source: On the other end of the spectrum, open source language models contribute to collaborative development and innovation. These models are released to the public with accessible source code and pre-trained weights, fostering a community-driven approach to furthering natural language processing capabilities.
We will eye on the following open source models further:
- Llama 2 (along with its variants), Purple Llama and Code Llama by Meta.
- Mistral LLM by Mistral AI.
Commercial Large Language Models
GPT (Generative Pre-trained Transformer)
GPT 3.5

🚀 Introduction:
Launched on March 15, 2022, by OpenAI(a leading AI research organization based in the United States) , GPT 3.5 stands as a crucial milestone within the GPT-3 series. This iteration is meticulously crafted on the foundation of the transformer model architecture.
🌐 Key Features:
Text Completion: It excels in coherent and contextually relevant text generation. Its proficiency in understanding and continuing given textual prompts makes it a versatile tool for many applications.
Interactive Conversations: A cornerstone in the evolution of ChatGPT , GPT 3.5 plays a pivotal role in the development of this free-to-use AI system designed for interactive and context-aware conversations. Its capabilities extend beyond text generation, enabling insights and task automation.
🌍 Applications:
Summarizing Input Text: Users can harness it to summarize lengthy pieces of text by providing a prompt. The model promptly generates a concise and coherent summary, showcasing its ability to distill information effectively.
Debugging Code: It aids in the identification of potential syntax errors and offering insightful debugging suggestions. This is accomplished without the need for direct access to the code execution environment, making the debugging process simpler.
🔄 Evolution:
GPT 3.5 marks a significant point in the evolutionary journey from GPT-1 to GPT-3, representing a culmination of advancements and refinements in natural language processing capabilities over successive iterations.
🔍 Technical Nuances:
Training Approach: The development of GPT 3.5 is grounded in a hybrid approach, combining both supervised learning and reinforcement learning. This training methodology contributes to the model's ability to understand complex patterns and nuances in languages.
Fine-Tuning: It undergoes a meticulous fine-tuning process, involving Human-in-the-Loop (HITL) feedback and AI feedback. This ensures alignment with intended objectives and compliance with desired policies, improving it's precision and adaptability.
GPT-4
🚀 Introduction:
Launched on March 14, 2023, GPT-4 emerges as the fourth iteration in the impressive GPT series developed by OpenAI. This model represents a significant leap forward in natural language processing capabilities, having an astounding 1.76 trillion parameters to enhance its understanding and generation of human-like language.
💼 Accessibility:
GPT-4 is accessible through the ChatGPT Plus subscription, available on the OpenAI website. Users can also leverage the model through OpenAI's API, providing a versatile platform for integrating GPT-4's capabilities into multiple applications and services.
💰 Subscription Fee and API Pricing:
To unlock the full potential of GPT-4, users can subscribe to the ChatGPT Plus service for $20 per month.
Additionally, API access is available with an extra fee based on the number of tokens required, offering flexibility for different usage contexts and lengths.

🌐 Enhancements:
Multimodal Capabilities: GPT-4 distinguishes itself with its ability to process both text and images which is an evolution that broadens its applicability across diverse multimedia content.
Context Window: The context window of GPT-4 has been expanded significantly from 4,096 to an impressive 32,768 tokens that helps in generating more extensive and nuanced information for better performance.
GPT-4 Turbo and GPT-4 Turbo with Vision: These specialized versions, announced in November 2023, introduce a 128K context window, further pushing the boundaries!
💻 Applications:
Content Creation and Marketing: It helps businesses to generate high-quality and engaging materials across multiple formats. tailored to specific audiences.
Software Development: Useful for software developers, this model can generate code snippets for specific tasks, saving time and effort in writing repetitive code.
Healthcare: GPT-4's impact on healthcare has particularly been shown in diagnostic imaging. The model showcases its precision by accurately analyzing medical images such as X-rays, MRIs, and CT scans. This capability enhances the speed and accuracy of disease detection, assisting radiologists in providing early diagnoses and improving overall patient care.
Claude

🚀 Introduction:
Launched on March 14, 2023, by Anthropic, it is distinct in its design philosophy, engineered to be a helpful, honest, and harmless AI system, prioritizing ethical and user-centric principles in its development.
🌐 Capabilities:
Accessible through both a user-friendly chat interface and an API available in the developer console for conversational and text processing tasks. Its capabilities extend to understanding and generating human-like language.
💼 Use Cases:
Claude has many applications, including summarization and searching, creative and collaborative writing, question-and-answer scenarios, coding tasks, and more. Its adaptability to different contexts positions itself as a multifunctional AI solution catering to a range of user needs.
🛠 Two Versions Available:
Anthropic offers two distinct versions, Claude, the regular version, provides a comprehensive set of features, while Claude Instant offers a lighter, more cost-effective alternative that significantly enhances processing speed without compromising functionality.
🏆 Real-World Impact:
In the legal domain, Claude, in collaboration with Robin AI, is reshaping the future of contracts due to its understanding of complex legal text that allows it to suggest user-friendly alternatives, streamlining the often intricate process of legal document creation. Additionally, in the digital media sector, Claude partners with AssemblyAI to power APIs for transcription, demonstrating its ability to understand and process audio data at scale. Constitutional AI (CAI) leverages Claude's capabilities to shape AI outputs based on the fundamental principles of helpfulness, harmlessness, and honesty.
👩💼 Claude for Business:
Anthropic extends Claude's functionality to businesses through its API, providing access to a limited set of customers and researchers!
Bard

🚀 Introduction:
Launched on February 6, 2023, Bard by Google is a venture into experimental conversational AI. This innovative platform signifies a pivotal leap forward in the evolution of conversational large language models.
💡 Evolution:
Bard's roots trace back to LaMDA (Language Model for Dialogue Applications), a family of conversational large language models developed by Google. The model has undergone transformative upgrades, transitioning to PaLM, a 540 billion parameter transformer-based large language model developed by Google AI. The evolutionary journey culminates in the development of Gemini.
🚀 Capabilities:
Bard seamlessly integrates multimodal search functionality through Google Lens. This enables users to input not only text but also images, fostering more dynamic and intuitive interactions. The convergence of text and images enhances the user experience.
🌍 Global Language Access:
With support for over 40 languages, Bard emerges as a global conversational AI solution. Its multilingual capabilities ensure accessibility and utility on a worldwide scale, catering to a diverse array of users with different linguistic preferences.
🔄 Real-Time Applications:
Bard's Integration with Google Apps: One of its standout features is its ability to retrieve real-time information from various Google apps. From pulling in the latest emails from Gmail to accessing files on Google Drive, retrieving map directions, flight details, hotel bookings, and even fetching content from YouTube, Bard seamlessly integrates with Google's suite of applications for a holistic user experience.
Travel and Activity Recommendations: Leveraging its access to the latest reviews and vast amounts of travel-related data, Bard is adept at providing personalized travel recommendations. From suggesting destinations to offering travel tips, Bard assists users in planning memorable and informed journeys.
Comparative Analysis with Charts: Bard has the capability to compare research and data. By generating charts that highlight the similarities and differences between two articles, Bard facilitates a deeper understanding of the focus and perspective of each piece, aiding users in comprehensive data analysis and decision-making.
Comparing different commercial models
- Based on accuracy: In a comprehensive evaluation across 27 subcategories, GPT-4 achieves the highest accuracy at 84.1%, outperforming ChatGPT, Claude, and Bard. The success of GPT-4 and ChatGPT is attributed to iterative refinement and incorporation of public feedback, leading to superior language understanding. Despite proficiency in reading comprehension, models struggle in reasoning tasks, with Bard occasionally introducing sensitive topics in responses.
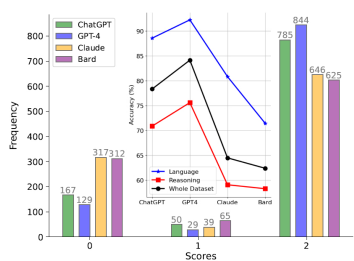
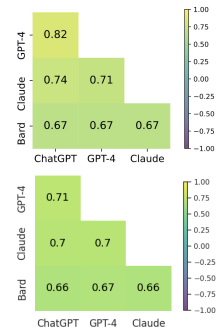
- Based on Correlation among models: Pearson correlation analysis reveals strong correlation (0.82) between GPT-4 and ChatGPT, while Bard exhibits weaker correlations (0.67) with other models across various categories. Examining cosine similarity using text embeddings shows that ChatGPT and GPT-4 have the highest similarity (0.71), with Bard again demonstrating less similarity to other models.
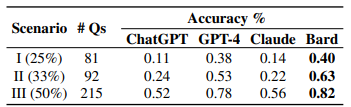
- Based on Wordsmiths MCQ: The Wordsmiths-MCQ dataset introduces scenarios for automated model evaluation:
- Scenario I (25% Chance): Questions with one correct and three incorrect answers.
- Scenario II (33% Chance): Two correct and two incorrect answers.
- Scenario III (50% Chance): Three correct and one incorrect answer.
- In this evaluation, Bard stands out with the highest accuracy, surpassing ChatGPT, Claude, and GPT-4. Notably, GPT-4 performs consistently well but is outperformed by Bard in this specific context.
Overall Performance
- GPT-4 consistently outperforms ChatGPT, Claude, and Bard across a diverse range of categories, showcasing its robust and versatile capabilities.
- Broad Consistency: GPT-4's dominance extends across 10 out of 12 main categories, highlighting its broad applicability and excellence in diverse tasks.
- Adaptability and Improvement: GPT-4's iterative evaluation and refinement process, coupled with public feedback, underscore its adaptability, continuous enhancement, and overall superiority.
- Correlation and Integration: Correlation analyses affirm GPT-4's strong agreement with ChatGPT, suggesting potential benefits in creating ensemble models for improved overall performance.
Open-source Large Language Models
Llama-2

🚀 Introduction:
Meta, in collaboration with Microsoft, unveiled Llama 2 on July 18, 2023. This joint endeavor aims to redefine text generation and comprehension, leveraging cutting-edge technology to provide users with a sophisticated and contextually aware open-source AI experience.
🌐 Key Features:
Text Comprehension: Llama 2 excels in coherent and contextually relevant text generation. Its advanced language understanding capabilities enable it to generate meaningful responses, contributing to a more natural and engaging user interaction.
Interactive Conversations: Its capabilities extend beyond standalone text generation, contributing to the evolution of AI systems that can understand and respond to user inputs with increased sophistication.
🌍 Applications:
Summarizing Input Text: It allows users to submit extensive pieces of text along with prompts, enabling the generation of concise and accurate summaries for quick and relevant insights.
Debugging Code: The model's ability to identify syntax errors and suggest debugging solutions contributes to the improvement of code quality, streamlining the software development process.
🔍 Technical Nuances:
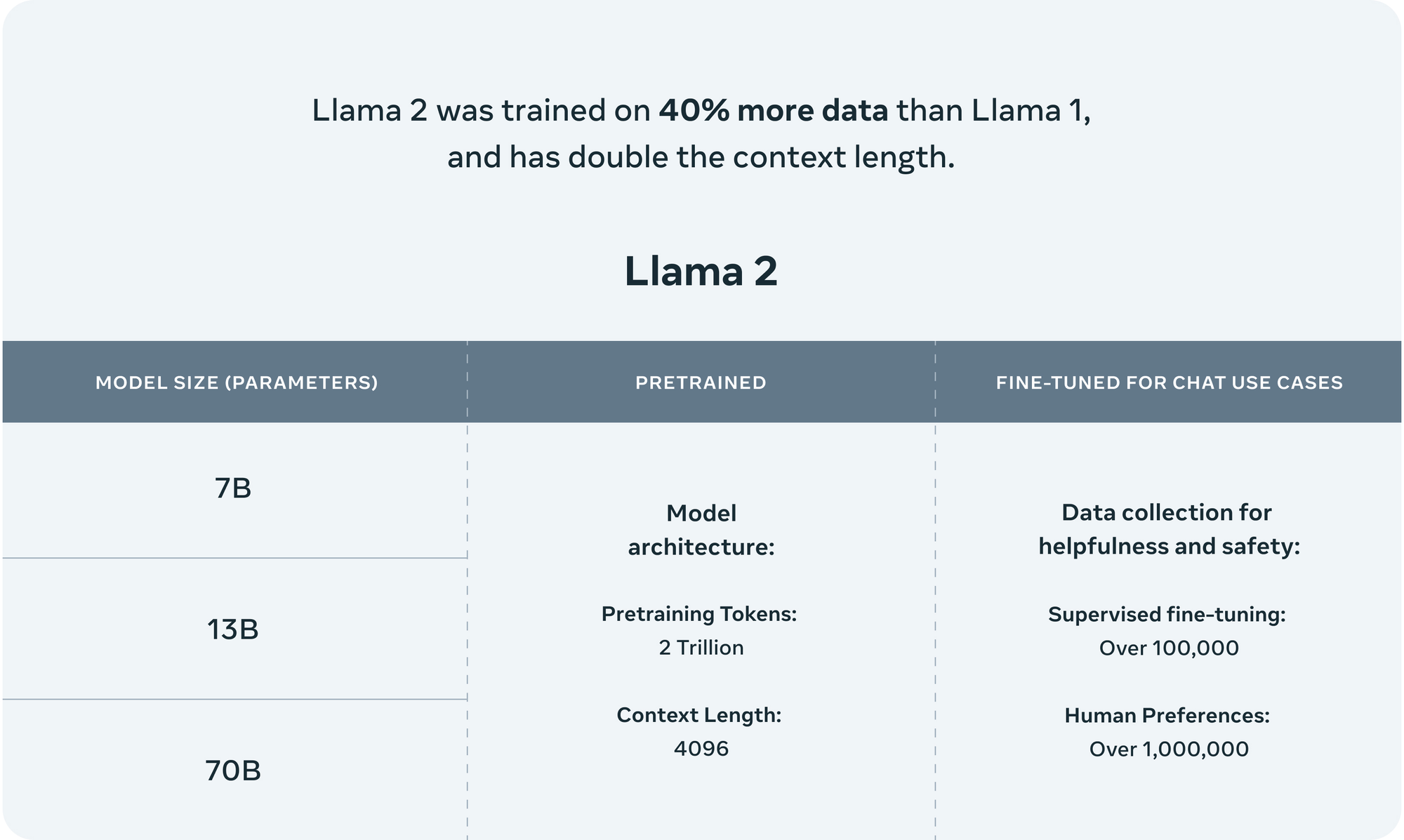
Training Approach: Llama 2 employs a comprehensive training approach, initially pretraining on publicly available online data sources. Subsequently, the model undergoes fine-tuning with over 1 million human annotations, resulting in the creation of Llama Chat. This two-step process ensures a robust and contextually aware language model.
Safety Measures: It incorporates safety measures to ensure helpful and secure interactions. Reinforcement learning from human feedback, including rejection sampling and proximal policy optimization (PPO), is implemented to enhance the model's safety and reliability in various conversational scenarios.
Model Specifications:
- Llama 2 7B: Trained over 184,000 GPU hours, this model is compact yet powerful, suitable for applications like enterprise chatbots and custom data training.
- Llama 2 13B: With 368,000 GPU hours of training, this model strikes a balance between size, comprehension, and world knowledge, making it suitable for web applications and advanced content writing.
- Llama 2 70B: Trained for over 1,720,000 GPU hours, this variant offers maximum world knowledge and comprehension, making it ideal for scalable architectures, education, and e-commerce applications.
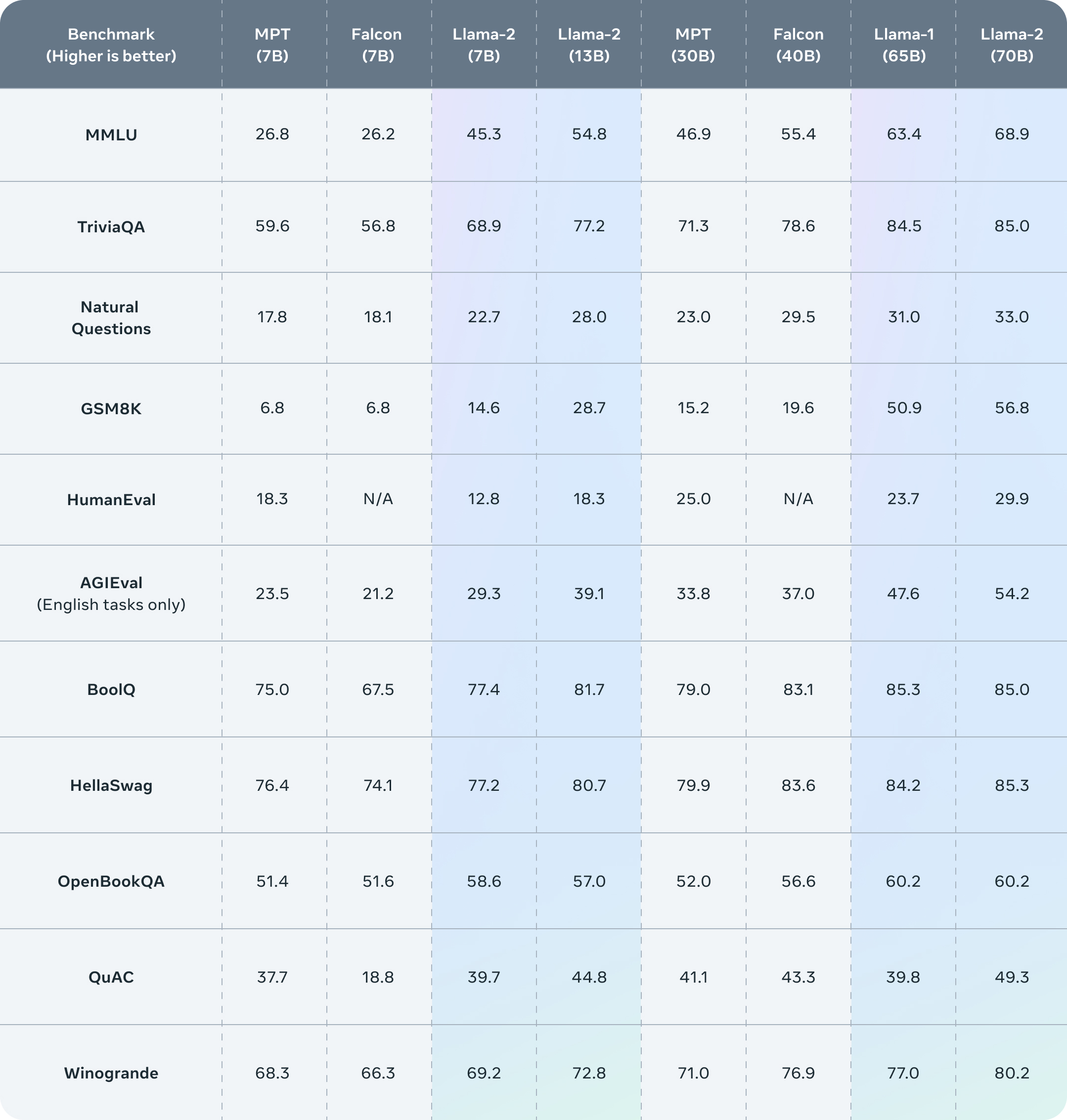
Compared to other open source models, Llama-2 (with 70 billion parameters) performs significantly well.
Purple Llama

🚀 Introduction:
Launched with a commitment to foster responsible generative AI, Purple Llama provides trust and safety tools for developers. This initiative is rooted in aligning with Responsible Use Guide best practices, aiming to create a more secure and reliable landscape for the development and deployment of large language models (LLMs).
🌐 Key Components:
CyberSec Eval: Purple Llama introduces CyberSec Eval, which establishes industry-wide benchmarks for assessing the cybersecurity safety of large language models. This includes metrics for quantifying risks associated with model outputs, evaluating the security of code suggestions, and tools designed to resist the generation of malicious code.
Llama Guard: Another integral component, Llama Guard, is an openly-available model designed to check and filter inputs and outputs of large language models. It demonstrates competitive performance on established benchmarks and is customizable for developers, providing a tool that fosters a safer open ecosystem.
Collaboration and Ecosystem: Purple Llama embraces open collaboration with industry leaders, organizations, and developers. Noteworthy partnerships include collaborations with the AI Alliance, AWS, Google Cloud, Microsoft, and other key stakeholders.
Purple Teaming Philosophy: Purple Llama adopts a purple teaming philosophy for generative AI, combining both offensive and defensive strategies. This approach involves collaborative efforts to rigorously test and assess the security and reliability of large language models.
🌍 Applications:
Purple Llama's initiatives have tangible applications in the real-world development and deployment of large language models. These include real-time assessment of cybersecurity risks associated with model outputs, filtering and securing inputs and outputs of large language models using Llama Guard, and fostering collaboration for responsible development within the generative AI community.
Code Llama

🚀 Introduction:
Code Llama emerges as a powerful tool designed to cater to the evolving needs of developers. This innovative platform is tailored to bridge the gap between natural language and coding, providing a versatile solution for a wide array of coding-related tasks.
🌐 Key Features:
Diverse Models Catering to Needs: Code Llama offers a trio of variants to meet specific requirements. The foundational Code Llama serves as a versatile model, while Code Llama - Python specializes in tasks related to the Python programming language. Additionally, Code Llama - Instruct is fine-tuned for comprehending and executing natural language instructions.
Unmatched Performance on Code Tasks: Code Llama sets itself apart by outperforming publicly available Large Language Models (LLMs) on a spectrum of code-related tasks, including code completion and debugging. The 34B variant, in particular, showcases exceptional performance in established benchmarks like HumanEval (53.7%) and Mostly Basic Python Programming (56.2%).
Tailored Variations for Specialized Use Cases: The specialization of Code Llama variants extends to fine-tuned models for specific use cases. Code Llama - Python, fine-tuned on an extensive dataset of 100 billion tokens of Python code, excels in tasks specific to Python-centric development.
🌍 Applications:
Efficient Code Generation and Comprehension: It facilitates efficient code generation and comprehension. Developers can leverage its capabilities to streamline coding processes, enhance productivity, and ensure the accuracy of generated code.
Specialized Python-centric Tasks: Code Llama - Python proves invaluable for developers immersed in Python-centric tasks. Its fine-tuned model, drawing on an extensive dataset of Python code, enables precise and context-aware interactions, catering specifically to the nuances of Python programming.
Natural Language-Driven Coding Instructions: Code Llama - Instruct emerges as a pioneering solution for natural language-driven coding instructions. Developers can interact with the model using plain language instructions, fostering a more intuitive and user-friendly coding experience while ensuring that the responses align with user intentions.
Mistral

🚀 Introduction:
Developed by Mistral AI, Mistral LLM stands as an influential player in the realm of large language models. With a decoder-based architecture boasting 7 billion parameters, Mistral LLM is engineered to deliver advanced natural language processing capabilities.
🌐 Key Features:
Model Variants: Mistral LLM comes in two distinct variants, each designed to cater to specific needs. The foundational Mistral LLM employs a decoder-based architecture with 7 billion parameters, providing a robust model for natural language processing tasks. On the other hand, Mistral LLM MoE 8x7B adopts a Mixture of Expert (MoE) architecture, featuring eight experts, each equipped with seven billion parameters. This variant adds a layer of complexity and specialization to address a broader spectrum of requirements.
Benchmark Superiority: Benchmark comparisons position Mistral LLM as a consistent frontrunner in the competitive landscape of large language models. Mistral LLM consistently outperforms models like Llama 2 13B, and notably, Mistral 7B competes on par with Llama 34B. This benchmark superiority underscores the exceptional performance and efficiency of Mistral LLM across various metrics.
🌍 Applications:
Mistral LLM finds application in a myriad of natural language processing tasks, including:
Text Generation, Summarization, and Question-Answering: The core strength of Mistral LLM lies in its ability to generate coherent and contextually relevant text. It excels in summarizing information and providing insightful responses to user queries, making it a versatile tool for content creation and information extraction.
Processing Image Inputs for General Questions: Mistral LLM's capabilities extend beyond traditional NLP tasks. It can process image inputs to generate responses for general questions, showcasing its versatility in multimodal applications.
Versatile Natural Language Processing Tasks: Mistral LLM is designed to handle a diverse range of natural language processing tasks. Whether it's crafting creative text, summarizing lengthy articles or providing nuanced answers to user queries.
Comparing different open-source models
In a comparative analysis, Mistral 7B Instruct and Llama 7B Chat models underwent evaluation using Eleuther AI's assessment harness across multiple benchmarks. The experiments were conducted on Predera's AIQ engine, utilizing a single GPU. These benchmarks tested the models' language understanding, generation, reasoning, question-answering, and instruction-following capabilities.
Intrinsic Knowledge Benchmarks:
- MMLU and CMMLU: Measure the models' knowledge in various subjects, spanning mathematics, history, computer science, law, astronomy, and more.
- Arithmetic, MathQA, OpenBookQA: Assess mathematical reasoning and understanding of science-related questions.
- ARC, Truthful QA, Hendrycks Ethics: Test reasoning abilities and evaluate the model's understanding of ethics and morality.
.png)
Result Analysis: Mistral 7B showcased superior performance across most intrinsic knowledge benchmarks, demonstrating significant advantages in Truthful QA and Arithmetic.
Reasoning Benchmarks:
- Hella Swag, Big Bench Hard, PIQA: Evaluate common-sense reasoning through multiple-choice questions and reasoning about physical common sense.
- ANLI, Winogrande, SWAG: Assess reasoning capabilities through adversarial datasets, entailment questions, and grounded commonsense inference.
.png)
Result Analysis: Llama 7B outperformed Mistral 7B on the Big Bench Hard dataset, while both models performed closely on other reasoning benchmarks.
Question Answering Benchmarks:
- RACE, BoolQ, DROP: Evaluate reading comprehension, boolean question answering, and discrete reasoning over paragraphs.
.png)
Result Analysis: Both Mistral 7B Instruct and Llama 7B Chat showed similar performance on question-answering benchmarks, struggling particularly on the DROP dataset.
Summary:
.png)
Mistral 7B demonstrated consistent superiority over Llama 7B in intrinsic knowledge tasks, while Llama 7B exhibited a slight advantage on Big Bench Hard reasoning tasks. Question-answering benchmarks showed similar performance for both models. These evaluations provide valuable insights into the models' strengths and areas for improvement, highlighting Mistral's overall better performance in diverse natural language processing tasks.
Companies currently using LLMs
A wide range of organizations are harnessing Large Language Models in their products as well as for providing different services. Here are a few of them:
GPT

Duolingo: It has integrated GPT-4 to enhance language learning for powering two key features: Role Play, offering AI-driven conversation practice, and Explain my Answer, providing contextual feedback on mistakes. It creates dynamic, immersive conversations, also it is currently available in Spanish and French with plans for expansion.
Stripe: The Applied Machine Learning team at Stripe employed GPT-4 for 15 prototypes, including support customization, answering support questions, and fraud detection. It also serves as a virtual assistant for developers, instantly extracting relevant information from extensive technical documentation.
Morgan Stanley: It is used for transformation of its wealth management operations. The AI model powers an internal chatbot, enabling comprehensive searches of the firm's extensive content library, providing instant access to insights, investment strategies, and market research.
Khan Academy: It has leveraged GPT-4 to introduce Khanmigo, an AI-powered assistant designed as a virtual tutor for students and a classroom assistant for teachers. This innovative tool aims to address the diverse learning needs of students by providing individualized assistance and fostering deeper understanding of concepts.
Claude

Netflix: It has empowered Netflix to enhance user experiences by understanding individual preferences. Using advanced algorithms, it analyzes users' past viewing habits, considering factors such as genres, actors, directors, and viewing history. With this rich dataset, it tailors personalized recommendations, suggesting shows and movies that align with each user's unique taste to increase user engagement.
Spotify: It elevates the creation of personalized playlists. It delves into users' listening histories, examining their favorite genres, artists, and song preferences. By employing Claude for personalized playlist generation, Spotify aims to extend user listening times and enhance overall satisfaction, offering a unique and tailored music experience for each user.
Bard

Gmail : Bard is being employed as a virtual assistant within Gmail, allowing users to manage emails more efficiently. Users can inquire about missed emails and seek summaries of document contents, making Bard a helpful tool for navigating and organizing Gmail content.
YouTube : Bard's integration with YouTube focuses on improving user engagement and interaction within the platform. Users can leverage Bard to ask specific questions about videos, seek additional information, or request personalized content recommendations.
Google Docs: Users can instruct Bard to find specific documents, copy text, create new content, and perform various actions within Google Docs. They can copy the generated text and paste it into Google Docs. Additionally, Workspace customers can use Duet AI, another AI assistant by Google, specifically designed for Google Docs.
Llama

Wells Fargo: Utilizes Meta's Llama 2 model, for internal purposes. It therefore enhances internal processes and operations through the application of generative AI.
Shopify: Employs Llama 2 in Shopify Sidekick, an AI-powered tool for small business owners. It automates tasks such as generating product descriptions, responding to customer inquiries, and creating marketing content, streamlining commerce site management.
LyRise: Integrates Llama for a chatbot in a talent-matching platform. It acts as a human recruiter, assisting businesses in finding and hiring AI and data talent from high-quality profiles in Africa across various industries.
Niantic: Implements Llama 2 in the Peridot feature for Pokemon Go. It generates environment-specific reactions and animations for pet characters in the game, enhancing user engagement and the interactive experience.
Mistral

Brave: It utilizes Mistral AI's open-source model Mixtral 8x7B for its conversational assistant Leo. It enhances privacy-focused web browsing experience, leveraging Mixtral 8x7B for conversational interactions.
Perplexity: It implements Mistral and Llama models in its search engine, with a custom-built open-source LLM used as a default in one of the final steps. It reinvents the search experience by utilizing Mistral's models, AWS Bedrock for fine-tuning, and incorporating multiple LLMs to formulate detailed and informative responses to user queries.
Conclusion
Our exploration of leading large language models reveals that AI is advancing at an exponential rate. Beyond specific model names, the collective progress signifies a broader stride in the field of artificial intelligence. As these models evolve, they exemplify the industry's commitment to pushing the boundaries of language comprehension and generation.
To stay abreast of the latest developments and discoveries in the world of large language models, you can subscribe to our newsletter here, we cater to all things AI related!

Our resources serve valuable insights for those keen on staying connected with the continuous advancements in large language models.
Stay tuned!



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}